W tym artykule wykorzystamy must have Data Engineera czyli Airflow – wspaniałe narzędzie do orkiestracji zadań z różnych usług.
Instalacja Docker i Airflow
Apache Airflow można zainstalować bezpośrednio, poprzez usługi chmurowe oraz lokalnie poprzez Dockera. My właśnie tak zrobimy.
Aby zainstalować Dockera lokalnie należy pobrać program Docker Desktop.
Aby postawić kontenery które utworzą nam apkę Airflow wykorzystujemy plik – docker – compose – wymagany generalnie do wszystkich aplikacji, które wymagają więcej niż jednego kontenera do pracy. Do tego wykorzystujemy plik Dockerfile, który opakowuje nam jednokonterową apkę lub współgra z docker-compose – polecenie build: . z docker-compose buduje obraz właśnie na podstawie pliku Dockerfile. Do tego dobrą praktyką jest dodanie pliku requirements.txt gdzie wypisujemy dodatkowe biblioteki (oraz ich wersje) wymagane do poprawnej pracy naszej aplikacji. Swoje pliki do Airflow umieściłem na repezytorium: https://github.com/dawid-brejecki/airflow-docker.
Rzut oka na plik docker-compose:

Dockerfile:

Requirements:
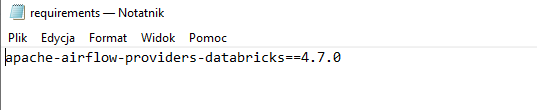
W pliku requirements umieściłem providera Databricks – ponieważ domyślnie nie ma go w obrazie Airflow. Pamiętajmy aby wskazywać odpowiednią wersję bibliotek – jeśli np. wskazałbym najnowszą, która nie jest kompatybilna z obrazem Airflow 2.8.1 kontenery zostałyby utworzone, ale aplikacja by nie zadziałała.
Umieszczamy te 3 pliki w folderze i w wierszu poleceń budujemy i uruchamiamy kontenery:
cd sciezka_folderu
docker compose build
docker compose up -d
Po utworzeniu pokażą nam się w aplikacji Docker-Desktop:
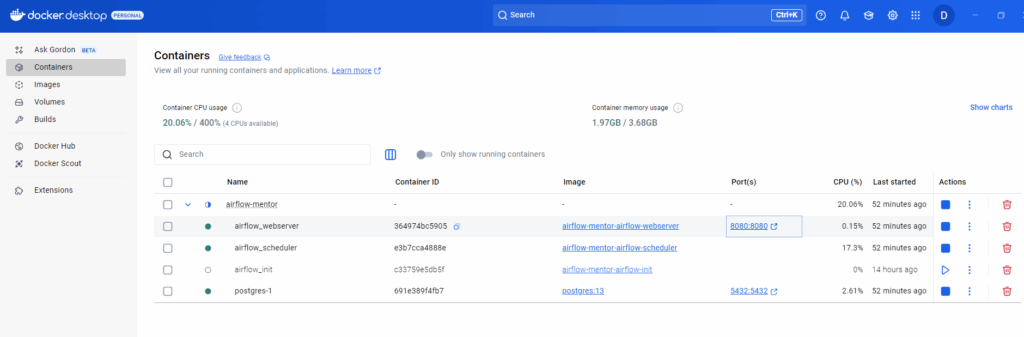
Airflow uruchamiamy wpisując adres w przeglądarce localhost:8080.
Na taki adres wchodzimy ponieważ taki był określony w pliku docker-compose. Ponadto w pliku docker-compose zaszylismy informacje o danych uzytkownika do logowania (airflow, airflow) oraz tworzenie folderu niezbędnego do działania – „dags”, gdzie wrzucamy DAG-i w formie skryptów pythonowych.
Po zalogowaniu do Airflow musimy utowrzyć connection do usług z jakich będziemy korzystać. W naszym przypadku chcemy tylko odpalić notebooka Databricks, więc takie connection tworzymy:
Przechodzimy do zakładki Admin-connections:
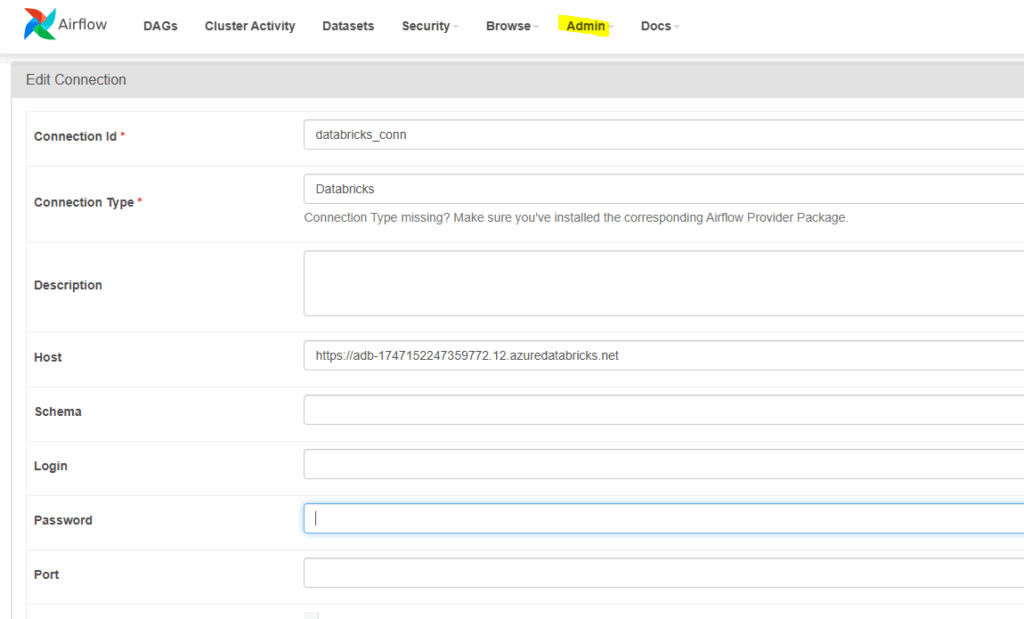
Wybieramy „Databricks” jako Connection Type oraz wpisujemy w pole Password access token do naszego workspace. Access token generujemy w Databricks – Settings – Developer – Access Tokens
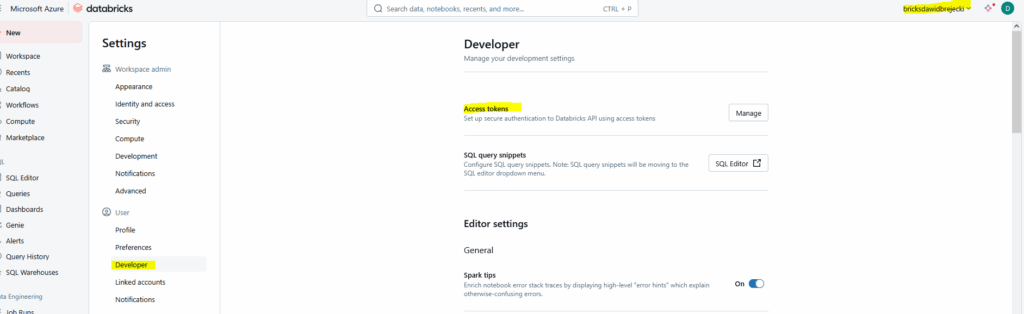
To wszystko jeśli chodzi o skonfigurowanie połączenia. Teraz tworzymy DAG-a, którego wrzucimy do lokalnego folderu dags:

To co najważniejsze to wykorzystanie operatora DatabricksSubmitRunOperator , wpisanie poprawnej nazwy connection do Databricks, ID klastra który użyjemy oraz ścieżki do notebooka.
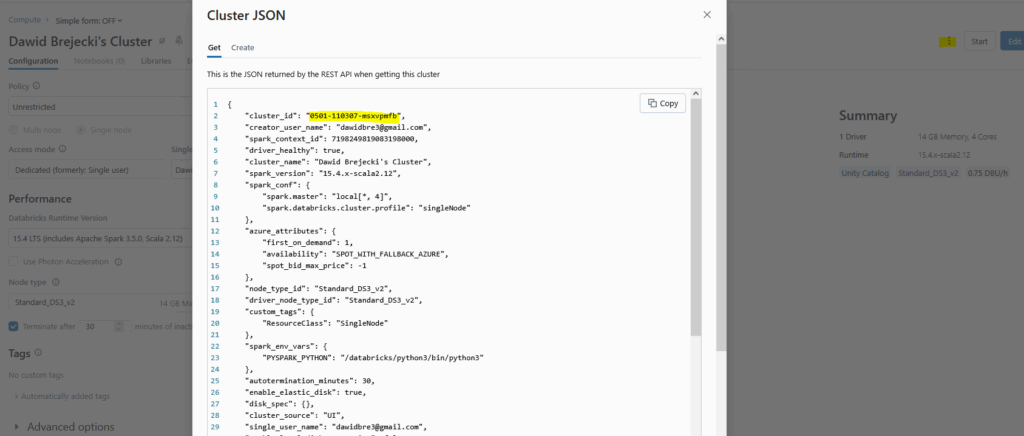
ID klastra znajdujemy klikając w Databricks nasz klaster – trzykropek – view JSON:
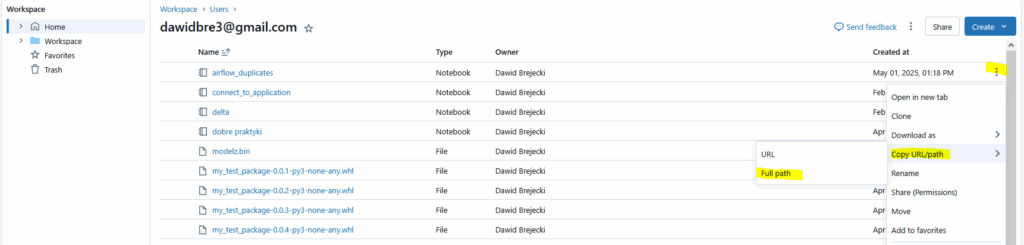
Sciezkę naszego notebooka pobieramy przechodząc do naszych notebooków – trzykropek-copy url/path – full path. Pomijamy pierwszy człon (Workspace/)
Po wklejeniu pliku python z naszym kodem DAG-owym w max kilka min DAG powinien pojawić się w GIU Airflow:

Możemy kliknąć „run” aby zobaczyć czy działa:
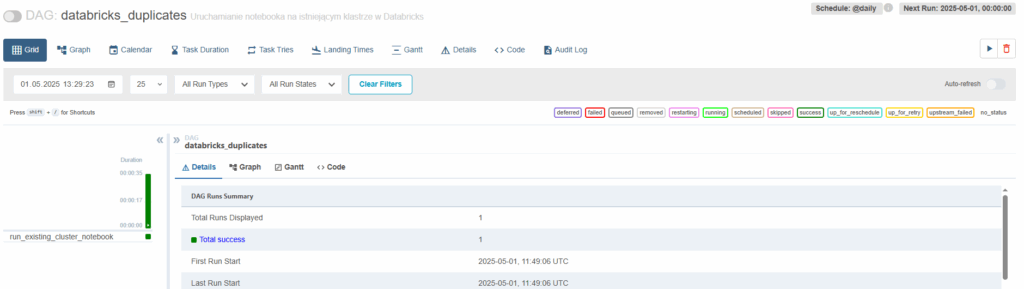
Uruchomienie zakończyło się sukcesem.
Oczywiście to był najprostszy DAG. W jednym DAG-u możemy uruchamiać wiele notebooków oraz łączyć się z wieloma usługami. Bardziej skomplikowane rzeczy będą zaprezentowane w następnych artykułach.
Jeszcze słowo o notebooku. Nasz notebook ma pobrać dane z Azure Data Lake Gen2, usunąć duble oraz zapisać do nowej lokalizacji w Data Lake:
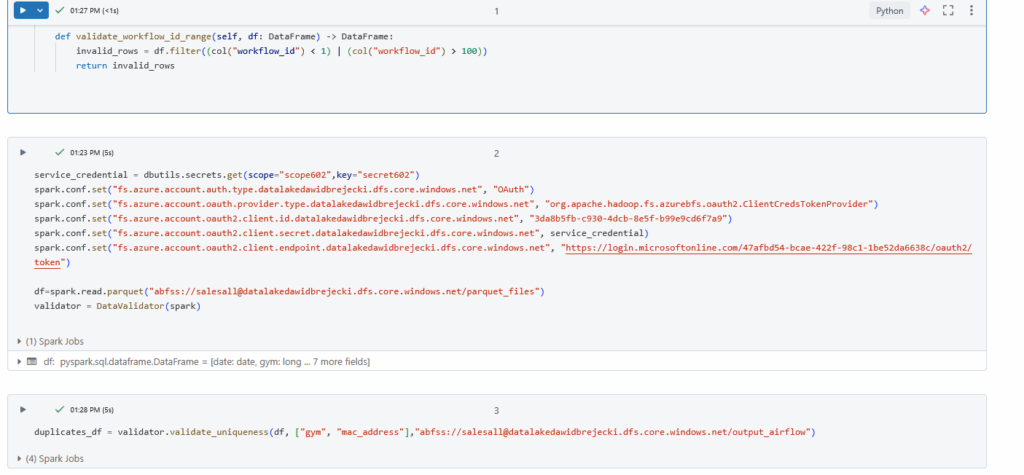
Aby poprawnie zadział trzeba ustawić connection do Data Lake. Jak widać, nie musieliśmy robić tego w Airflow, wystarczyło że było one w notebooku. To pokazuje naturę Airflow – on tylko uruchamia zadania danych usług, nie kopiując ich tasków.