Indeksy są jak ponumerowanie stron w książce. Ich stworzenie zajmuje pewną ilość czasu, ale
utworzenie indeksu dla kolumny (lub kilku kolumn) znacznie przyspiesza odpytywanie danej tabeli.
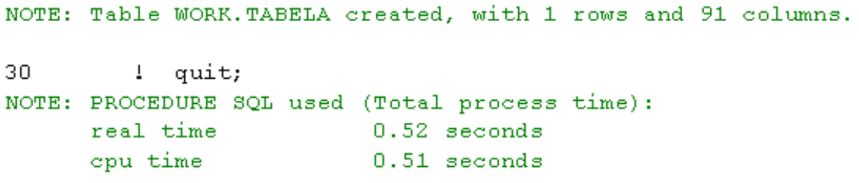
Zastosujmy najprostszy, domyślny indeks na tabeli o 91 kolumnach i 150 000 wierszach i porównajmy wydajność.
Napiszmy najprostsze zapytanie (SAS):
proc sql;
create table tabela as
select * from t1
where contractnumber ='99999999'
;quit;
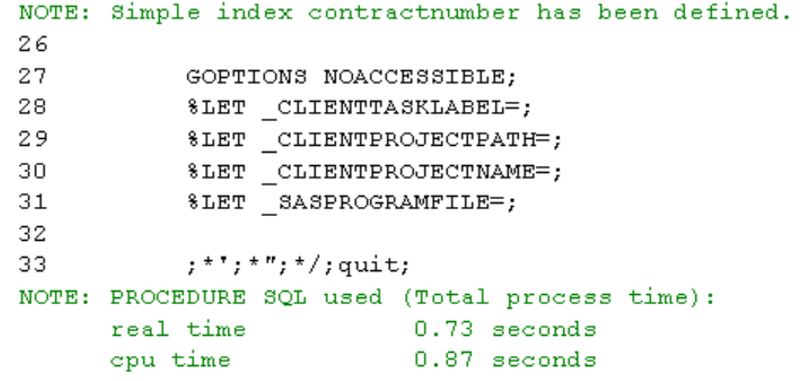
Tworzymy teraz w najprostszy, domyślny sposób indeks w SAS 4GL:
proc sql;
create index contractnumber
on t1 (contractnumber);
Urochomienie pierwszego zapytania po zastosowaniu indeksu:
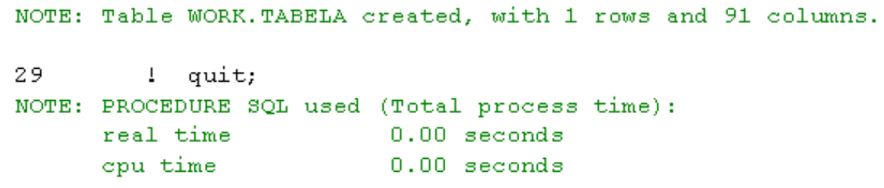
trwało mniej niż jedną setną sekundy, zatem różnica w wydajności jest ogromna.
Co ważne, indeks zostaje w tabeli na zawsze, do czasu jego usunięcia, nie trzeba zatem powtarzać tej czynności.
Samo tworzenie indeksu zajęło 0,73 s, warto zatem pamiętać aby tworzyć indeksy na kolumnach, które rzeczywiście są używane w filtrowaniu i łączeniu.
Kolejną kwestią związaną z indeksami, jest fakt znacznego spowolnienia operacji INSERT, MODIFY, UPDATE w tabelach z indeksami. Najlepszą praktyką jest usunięcie indeksu przed takim rodzajem operacji:
proc sql;
drop index contractnumber from t1;
I ponowne jego utworzenie po operacji INSERT/MODIFY/UPDATE.