Niezadowoleni do końca ze skuteczności modelu skoringowego (71%) postanawiamy wykorzystać pełen potencjał uczenia maszynowego i zastosować niezwykle popularny i skuteczny algorytm XGBoost (Extreme Gradient Boosting) Import pliku:
df = pd.read_csv(sciezkapliku.csv', encoding='latin-1', on_bad_lines='skip', sep=",")
Wiemy już które zmienne są skorelowane i je usuwamy:
drop_columns_list = ['height_cm','systolic','gripForce','broad jump_cm']
def col_to_drop(df, columns_list):
df.drop(columns = columns_list, inplace = True)
col_to_drop(df, drop_columns_list)
Przeprowadzamy obowiązkową standaryzację zmiennych ciągłych oraz zmianę wartości kategorycznych na liczbowe i dzielimy zbiór na testowy i treningowy:
column_names_to_not_normalize = ['docelowa','gender']
column_names_to_normalize = [x for x in list(df) if x not in column_names_to_not_normalize]
scaler = StandardScaler()
df[column_names_to_normalize] = scaler.fit_transform(df[column_names_to_normalize])
df['gender'] = np.where(df['gender'] == "M", 1,0)
target = df.pop('docelowa')
X_train, X_test, Y_train, Y_test = train_test_split(df, target, test_size = 0.2, random_state = 42)
W związku z tym, że zmienna docelowa jest niezbalansowana, poprzez parametr sample_weight staramy się ograniczyć tego wpływ na wyniki:
from sklearn.utils.class_weight import compute_sample_weight
sample_weights = compute_sample_weight(
class_weight='balanced',
y=Y_train
)
Trenujemy model i wyznaczamy zmienne o największym wpływie na wynik:
classifier = XGBClassifier()
classifier.fit(X_train, Y_train, sample_weight=sample_weights)
from xgboost import plot_importance
plot_importance(classifier)
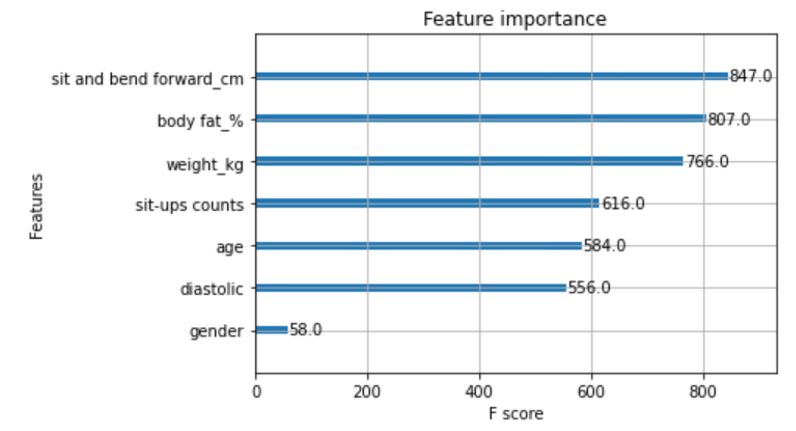
Jak widać wszystkie zmienne oprócz “gender” powinny zostać w modelu.
Usuwamy zmienną gender, trenujemy model jeszcze raz i obliczamy jego skuteczność:
drop_columns_list = ['gender']
col_to_drop(X_train, drop_columns_list)
col_to_drop(X_test, drop_columns_list)
classifier = XGBClassifier()
classifier.fit(X_train, Y_train, sample_weight=sample_weights)
Y_pred = classifier.predict(X_test)
cm = confusion_matrix(Y_test, Y_pred)
print(f'Accuracy: {accuracy_score(Y_test, Y_pred)}')
print(cm)

Poprawa w skuteczności względem modelu skoringowego jest ogromna. Ponadto, model dobrze rozróżnia zarówno obserwacje negatywne, jak i pozytywne.
Model jest dobry, więc zapisujemy go na przyszły użytek:
import pickle
filename = ‘sciezka/finalized_model.sav'
pickle.dump(classifier, open(filename, 'wb'))
Aby załadować i użyć na nowych danych:
classifier = pickle.load(open(filename, 'rb'))
p=classifier.predict(X_nowe_dane)