Kiedy używamy plików Parquet? Kiedy mamy bardzo dużo danych 🙂
Pliki parquet w porównaniu z plikami csv posiadają kilka zalet:
- zmniejszają wymagany rozmiar na dysku
- kolumnowy charakter plików umożliwia szybkie ładowanie danych
- wspierają partycjonowanie danych (zapis w podziale na określone przez nas cechy, przez co przy pobieraniu danych ładujemy tylko pliki z wymaganymi przez nas danymi)
Partycjonowanie
Partycjonowanie dzieli plik w zaleznosci od podanych cech. Partycjonowanie ma sens kiedy pracujemy z duzymi plikami min 100 MB – nie ma sensu dzielenie pliku na małe pliki i spowalnianie przez to spark. Sprawdzmy jak zapisac taki plik w taki sposób
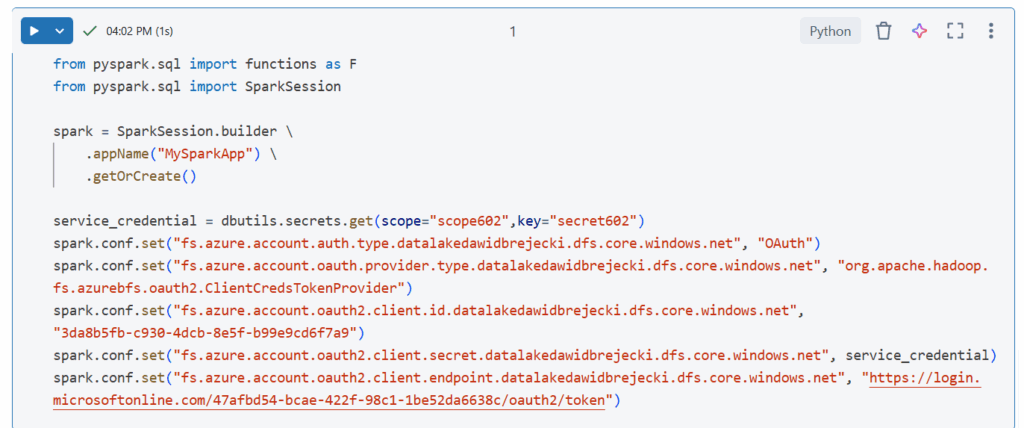
Łączenie z lokalizacją na Azure Data Lake:
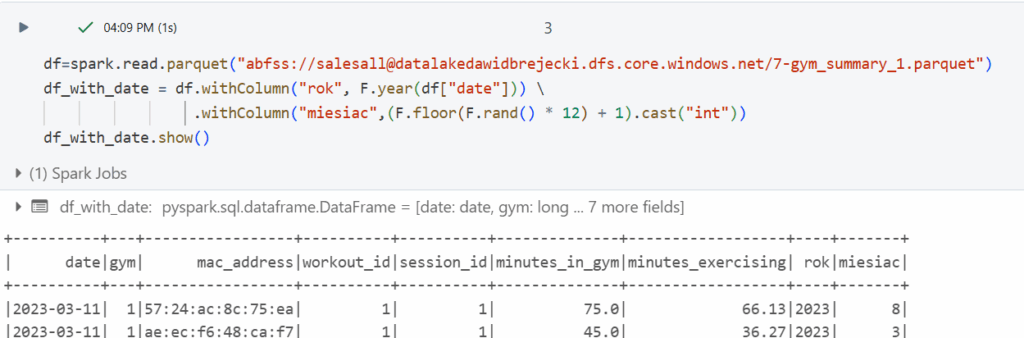
Przygotowanie naszego pliku – załadowanie pliku parquet, dodanie kolumny „rok” i „miesiąc” po których będziemy dzielić nasz plik
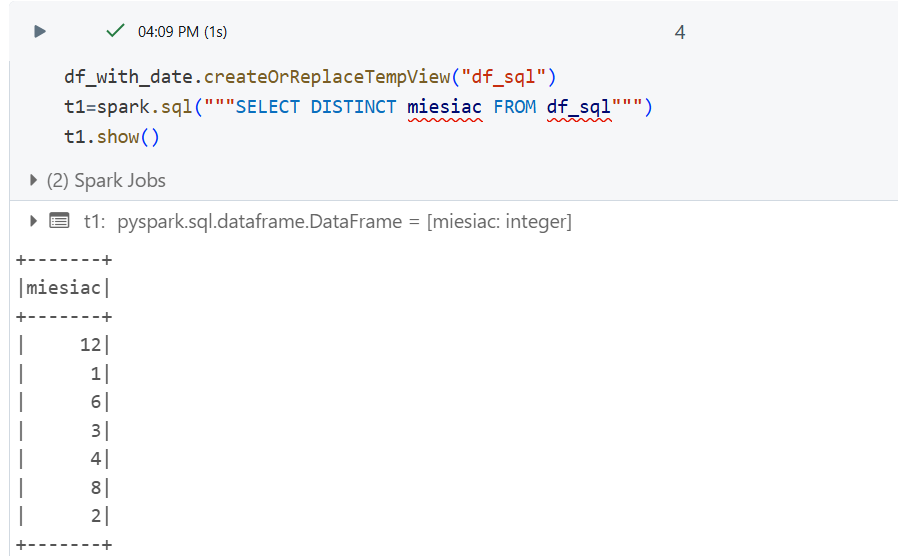
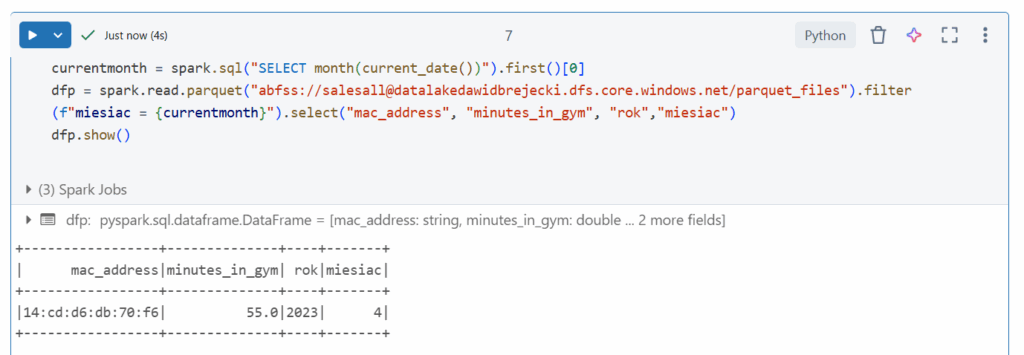
Sprawdzenie miesięcy w SparkSQL
Zapis partycjonowany do plików parquet
Partycjonowanie odbywa się w opcji „partitionBy”. Istotną opcją jest też mode „overwrite” – oznacza to że nadpisujemy istniejące pliki. Jest to dość niebezpieczne i najczęściej korzystamy z opcji „append” która dodaje pliki parquet do istniejących, dzięki czemu nie usuniemy żadnych danych (aczkolwiek jest wtedy ryzyko dubli – o tym później). Opcja kompresji „snappy” zmniejsza rozmiar danych zapisywanych na dysku.

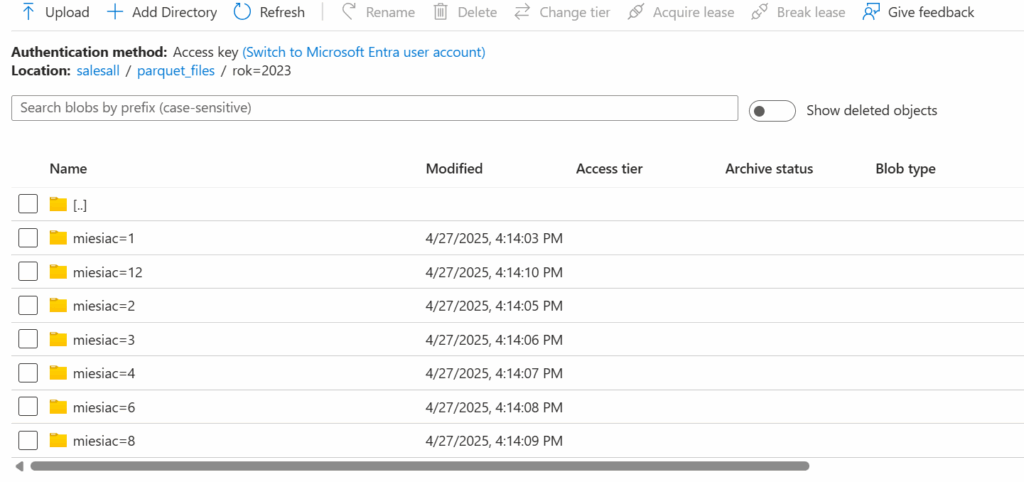
Rezultatem jest automatyczne stworzenie wielu folderów w naszym kontenerze z plikami:
Optymalne ładowanie danych
Teraz gdy mamy dane spartycjonowane i wiemy że będziemy np. korzystać tylko z danych z obecnego miesiąca możemy zapisać to w kodzie i dzięki temu załadujemy tylko jeden mniejszy plik. Ponadto dzięki opcji select możemy wybrać tylko interesujące nas kolumny (podstawowa zasada pisania wydajnych zapytań w SQL :))
Zapis z opcją „append” oraz aktualizowanie wartości
Zapiszmy ten jeden rekord z opcją „append”:
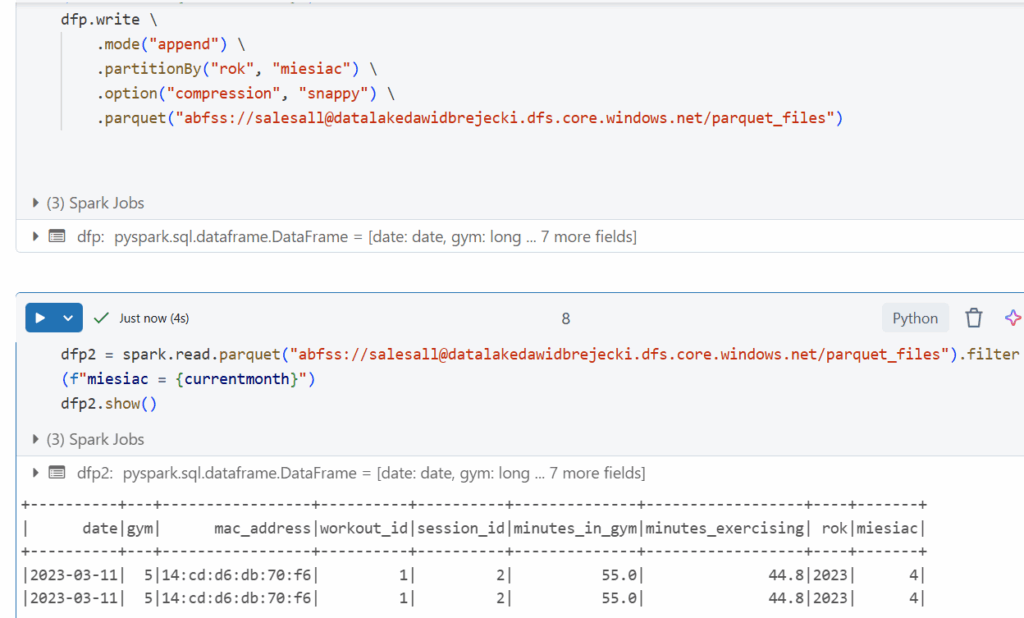
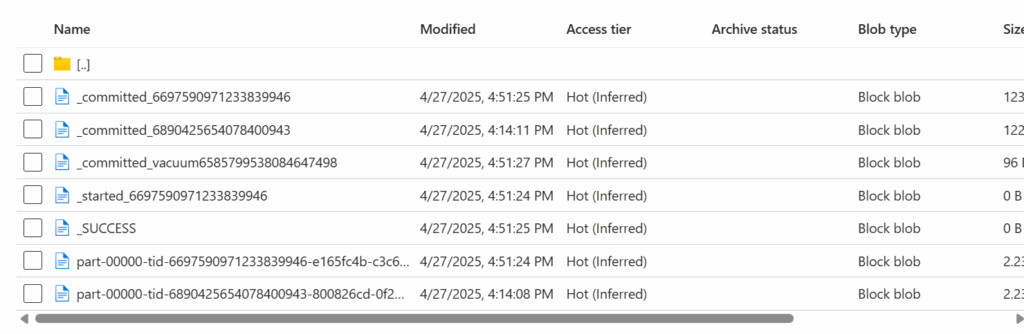
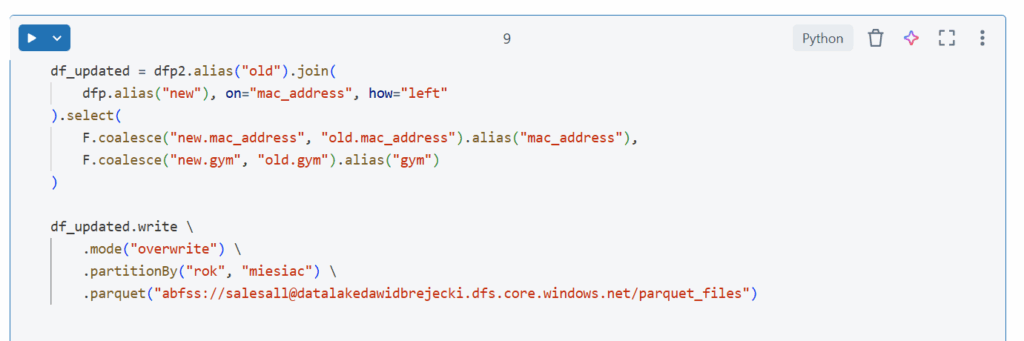
Jak widać został stworzony nowy plik parquet i rekord jest de facto zdublowany. Dzieje się tak dlatego że zapis do parquet nie obsługuje bezpośrednich operacji aktualizacji (jak w pracy z tabelami delta). Obejściem jest wtedy użycie klasycznego joina i wylistowanie kolumn oraz z jakich danych (nowych czy starych) mają zostać pobrane wartości
Schema
Praca z danymi parquet nie jest problemowa jeśli zapiszemy nową kolumnę do danych. Dane zostaną wtedy prawidłowo załadowane z dodaną kolumną.