Delta Table to po prostu open source’owy format zapisu tabel w Databricks. Zobaczmy co możemy na nich robić:
Tworzenie tabeli
Utwórzmy tabelę w bazie sales_unity w bazie test_baza:

Na końcu statementu możemy podać w jakich formacie utworzyć tabelę. Domyślnie jest zapisywana jak Delta Table więc nic nie musieliśmy dopisywać
Zasilanie tabeli
Wczytajmy plik z wolumenu „pliki” w tej samej bazie, zapiszmy do Dataframe i wybrane kolumny do tabeli.
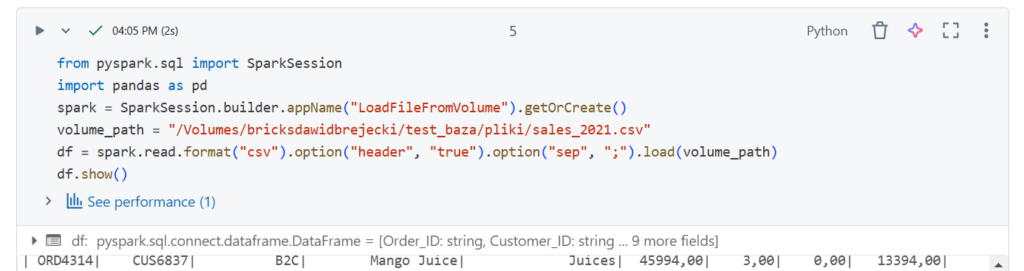
Oczywiście przy takich zadaniach mogą wystąpić błędy typu danych (szczególnie dla kolumn z datami).
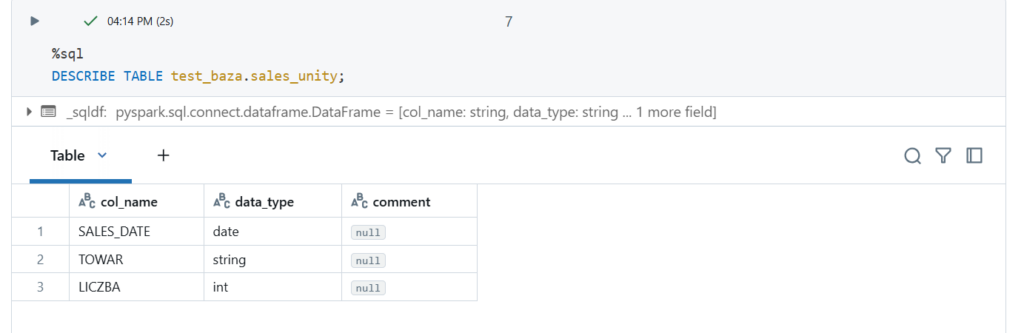
Spójrzmy jakie typy danych mamy w tabeli docelowej:
I w pliku:
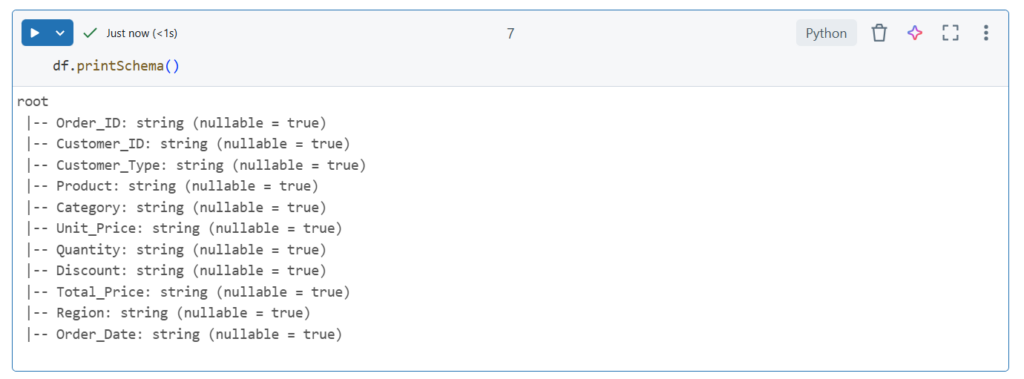
Jak widać same stringi. Musimy więc zmienić ich typ i ładujemy do bazy (zamiana nazw kolumn na te odpowiadające w tabeli docelowej nie jest konieczna, kolumny są wstawiane według pozycji, acz zalecana)
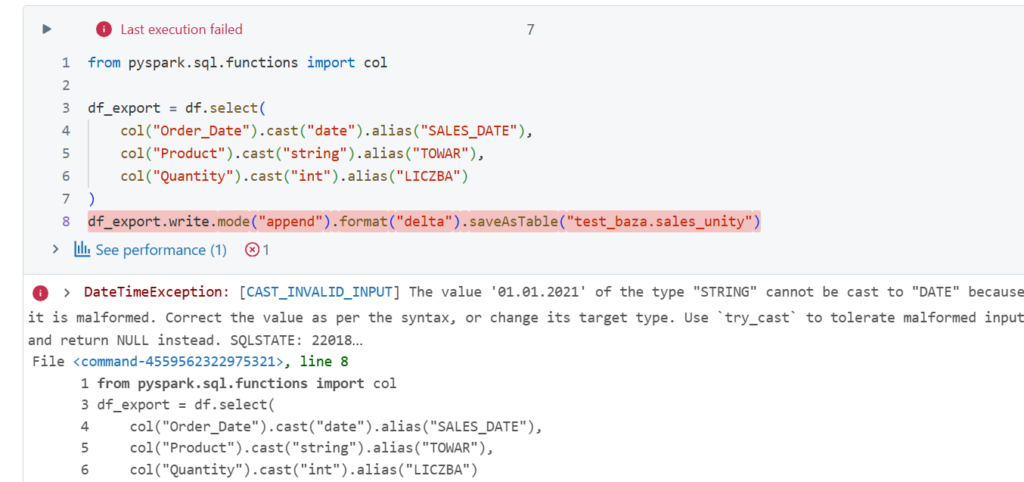
Pomimo zmiany typów danych wciąż jest błąd. Problem w tym że Spark nie potrafi zobaczyć daty w formacie 'dd.mm.yyyy’. Używamy więc wcześniej kodów pythonowych aby zmienić typ:
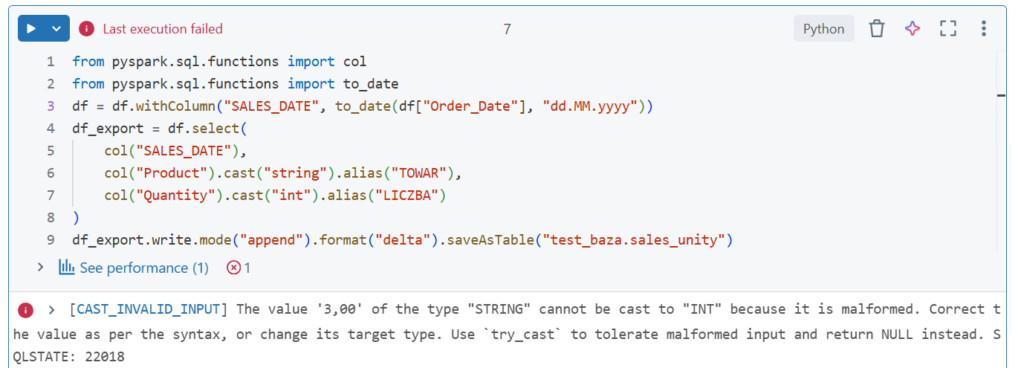
Tym razem błąd wystąpił dla kolumny Quantity. Musimy usunąć przecinek, zamienić na kropkę i na int. Użyjemy SQL;a:
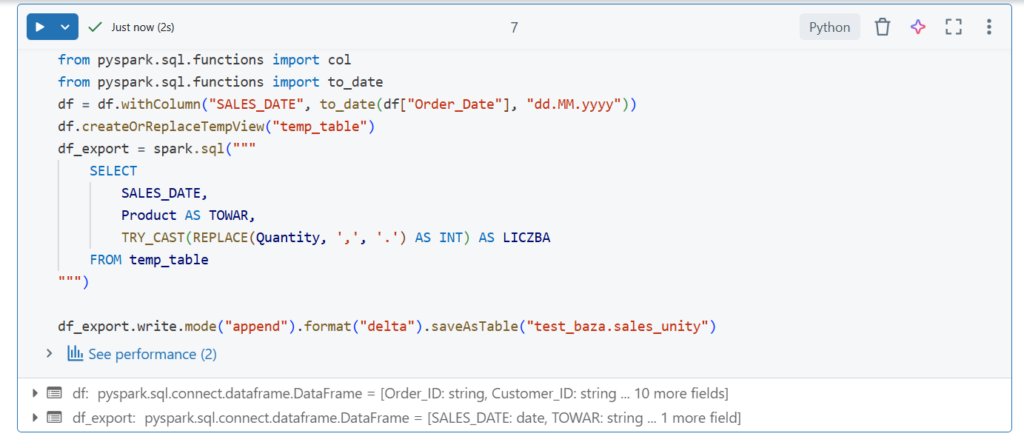
Teraz wszystko jest ok
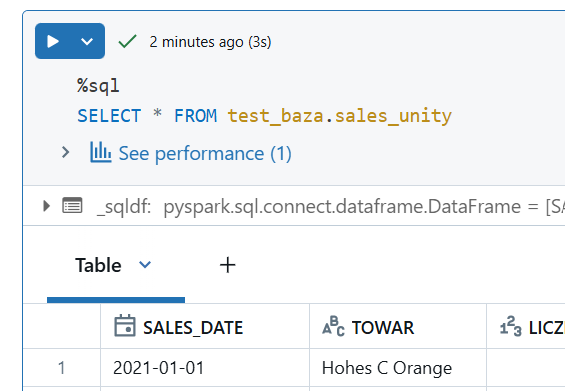
Zapis do nowej tabeli
Tabela sales_unity2 nie musi być utworzona, zapisujemy kodem w jednej linijce:

Zapis tabeli do zewnętrznej lokalizacji

Odczyt tabeli

Przeglądanie historii tabeli
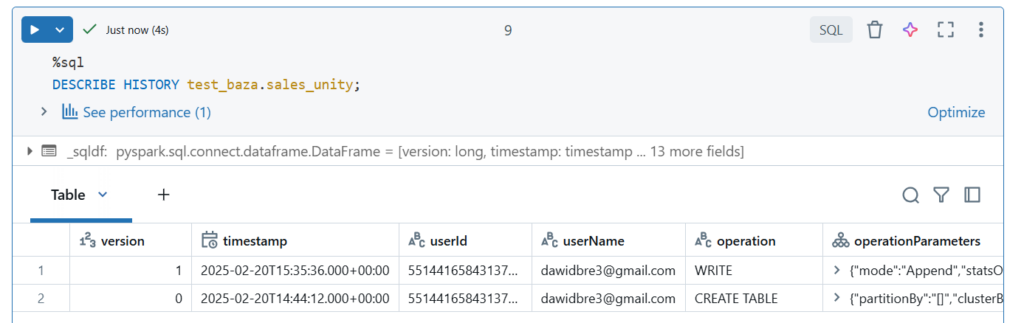
Wyświetlenie wybranej wersji
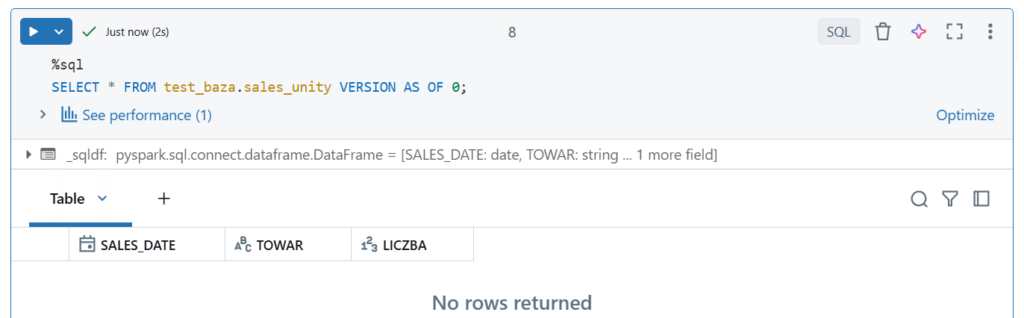
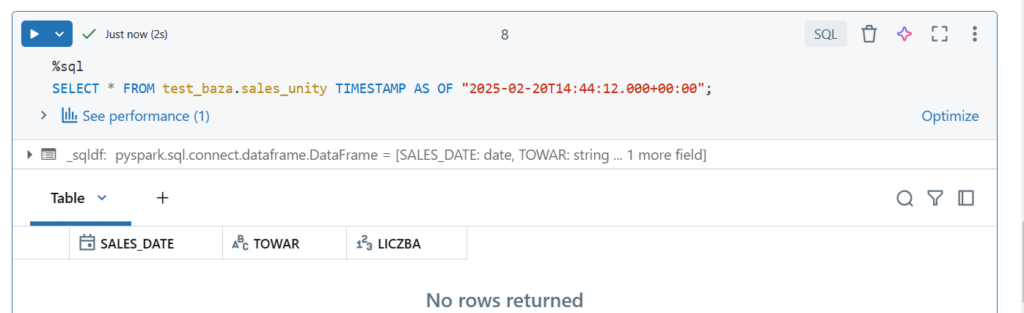
Wyświetlenie wersji z danego czasu
Powrót do wybranej wersji w czasie

Insert większej liczby kolumn niż tabela posiada
Ogólnie nie jest to dozwolony przypadek – dodatkowe kolumny się nie dodadzą. Możemy wtedy zmienić naszą główną tabelę dodając kolumnę instrukcją ALTER lub użyć następującego kodu: (główna tabela wtedy automatycznie się dostosuje)

Szczegółowe info o tabeli
