Czym są Delta Live Tables? Jest to framework ułatwiający budowanie potoków danych. Użyteczne szczególnie gdy mamy do obsługi więcej tabel (np. przy budowie architektury medalionowej).
Siłą Delta Live Tables są dekoratory zwiększające wysokopoziomowość kodu.
Aby zbudować pipeline dlt wybieramy pipelines w UI Databricks – new ETL pipeline. Określamy podstawowe konfiguracje – czy używamy opcji serverless czy tworzymy klaster na potrzeby uruchomienia potoku (zamyka się automatycznie po wykonaniu zadania)
Wybieramy też lokalizację tabel i widoków zmaterializowanych w Unity Catalog:
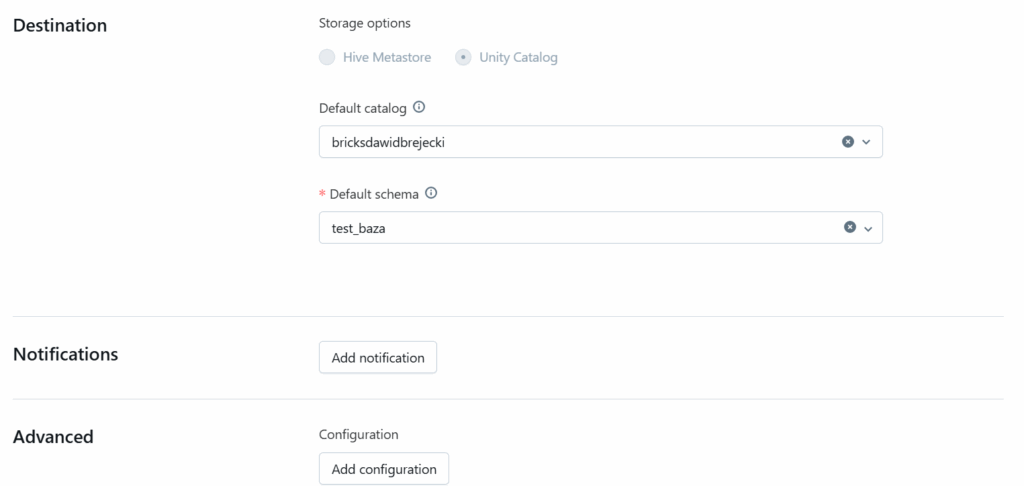
Można też ustawić scheduler uruchamiania pipeline.
Proces biznesowy wygląda tak:
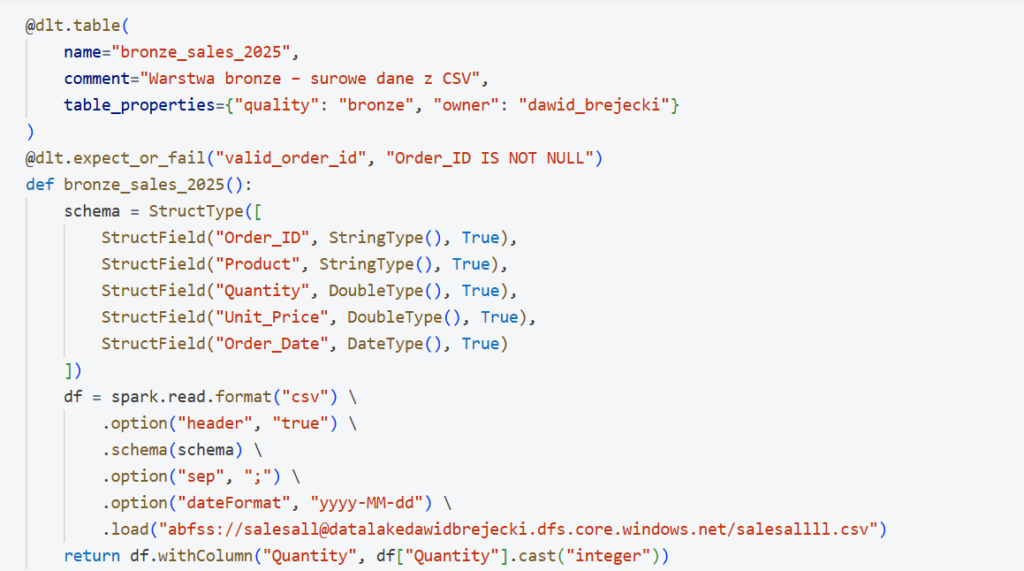
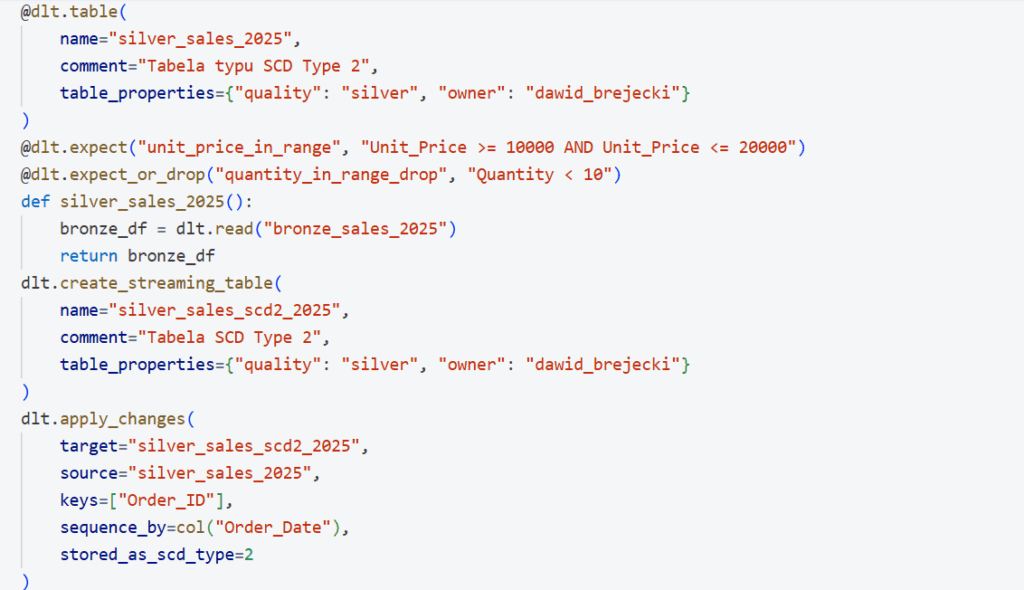
Należy pobierać codziennie dane z pliku csv znajdującego się na Azure Data Lake, zadbać o odpowiednią strukturę pobierania danych w tym odpowiedniego formatu daty, istnieje konieczność zamiany decimali na inty i zapis do warstwy brązowej. Walidacja danych na podstawie Order ID – przerywamy pipeline w razie błędu. W warstwie srebrnej walidujemy dane – część zapisujemy jako corrupt, część pomijamy. Aktualizujemy dane wg Order ID – weryfikacja po czasie w kolumnie Order Date. Stosujemy SCD 2 – czyli nie aktualizujemy rekordów, tylko dodajemy nową wersję (mamy pełny wgląd w historię). W warstwie gold agregujemy dane z pełnej tabeli silver.
Wchodzimy w notebook definujący pipeline.
Standardowy import bibliotek:

Tworzymy warstwę brązową:
Warstwa srebrna:
Warstwa gold:
