Ubranie naszego kodu w definicje, i dalej w moduły i biblioteki oraz lokalna praca nad skryptami z utworzeniem jobów w Databricks jest wzorem rozwiązań produkcyjnych. Oczywiście notebooki są idealne do eksperymentów i także mogą być podstawą jobów, jednak częściej podejście modułowe jest uważane za bardziej profesjonalne.
Clue naszej pracy jest rozbicie całego kodu w moduły – osobne pliki .py zawierające definicje wykonujące potrzebne operacje na danych. Moduł jest następnie importowany jako biblioteka w pliku main – który powinien zawierać tylko wywołania modułów i funkcji. Podejście to jest zbliżone do zasad programowania obiektowego.
Do pracy lokalnie nad oprogramowaniem polecam Visual Studio Code.
Wykorzystamy notebooka utworzonego w artykule: https://analitykdanych.eu/orkiestracja-notebookow-databricks-sposob-pierwszy-wywolywanie-notebooka-w-innym-notebooku/
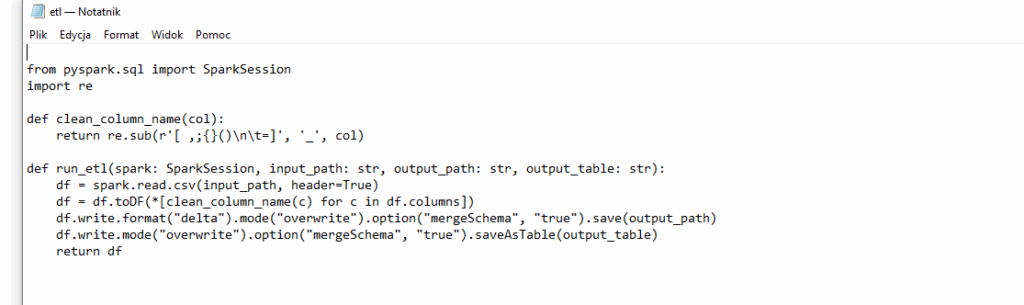
Widzimy że możemy rozbić notebooka na funkcję konfigurującą dostęp do Azure Data Lake oraz funkcję wykonującą naszą prostą ETL – ładowanie pliku i zapis do Delta
Tworzymy więc plik .py z konfiguracją Azure, nazwijmy go azure_config (będzie to nazwa biblioteki):
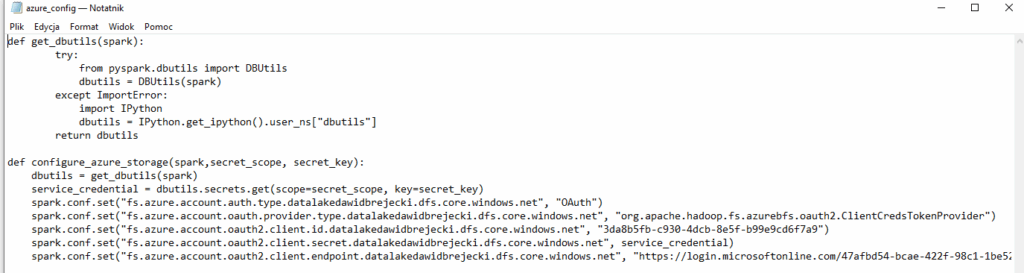
W związku z tym, że dbutils nie jest dostępne poza Databricks, musimy je wywołać z biblioteki pysparka
Kolejny plik nazwijmy etl.py:
Tworzymy teraz plik main.py z wywołaniem bibliotek i funkcji:
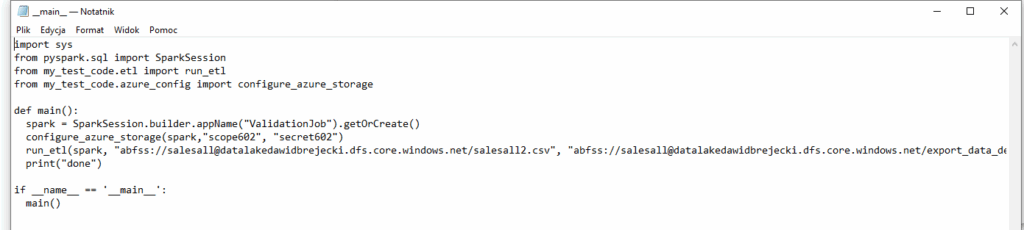
W pliku __main__.py tworzymy funkcję main(), która będzie wywołana przez joba. Spójrzmy na import funkcji. my_test_code jest nazwą folderu w którym umieściliśmy pliki .py:
Dodajemy także plik __init.py__, w którym dodajemy metadane jak autor czy wersja naszego programu:

Teraz tworzymy plik setup.py, który skomponuje nam nasz projekt w plik .whl który wgramy do Databricks. Zgodnie z dobrymi praktykami umieszczamy go luzem w naszym folderze:
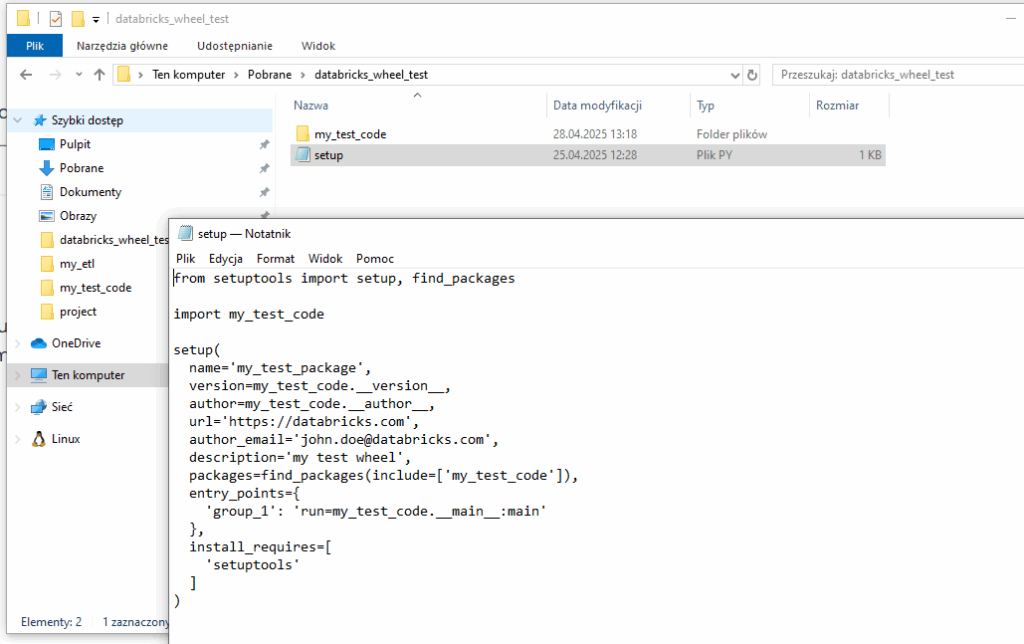
Kluczowymi polami są: name – nasza nazwa projektu, entry_points – wskazujemy tam nazwę entry_pointa oraz ścieżkę z nazwą funkcji która ma być odpalana przez joba. Może ich oczywiście być więcej. W polu packages wskazujemy folder w którym są pliki .py zamieniane na moduły.
To wszystkie pliki, które są potrzebne do utworzenia pliku .whl. Uruchamiamy wiersz poleceń, wchodzimy do lokalizacji naszego projektu i wywołujemy kod: python setup.py bdist_wheel

Skomponuje to nam plik w folderze dist.
Przechodzimy teraz do Databricks – wybieramy Job Runs – Jobs – Create Job
Wpisujemy dowolną nazwę w task_name, type – Python wheel, Package name – nazwę projektu określoną w pliku setup.py, Entry Point – nazwę naszego checkpointa uruchamiającego funkcję, Compute – tworzymy nowy klaster lub wybieramy spośród istniejących, Dependent libraries – uploadujemy utworzony lokalnie plik .whl
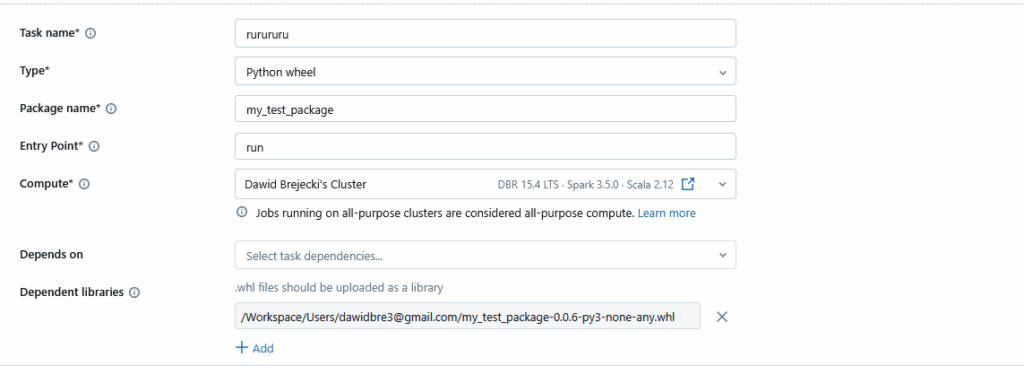
Klikamy Save i Run:
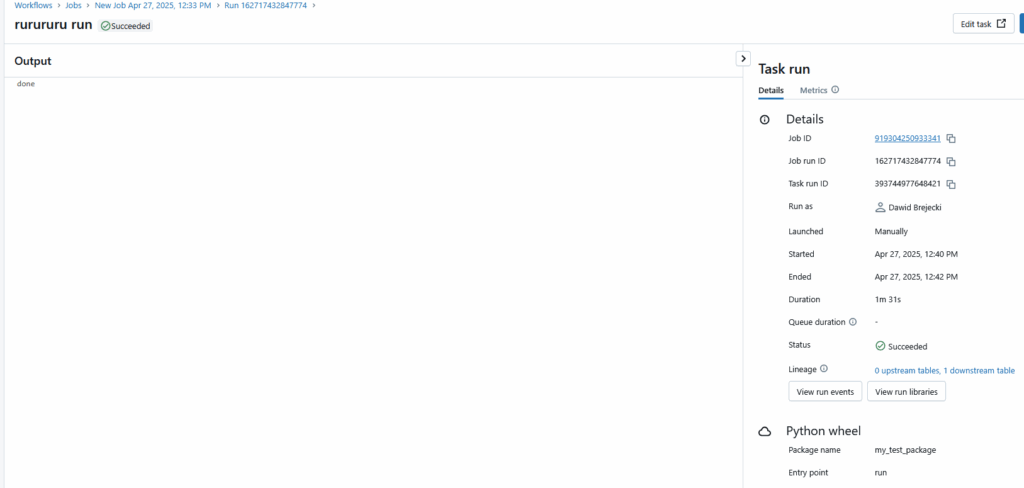
Wykonało się bez błędów.
Do naszego joba możemy dodać kolejny task. Dodamy np. notebooka z testami jednostkowymi:

Tworzenie taska z notebookiem jest znacznie prostsze i wystarczy po prostu wybrać notebooka z listy (źródłem może też być plik z repo):
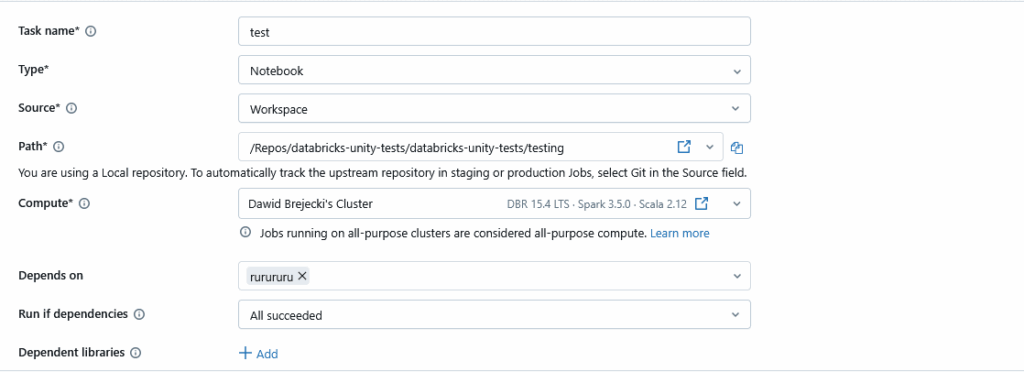
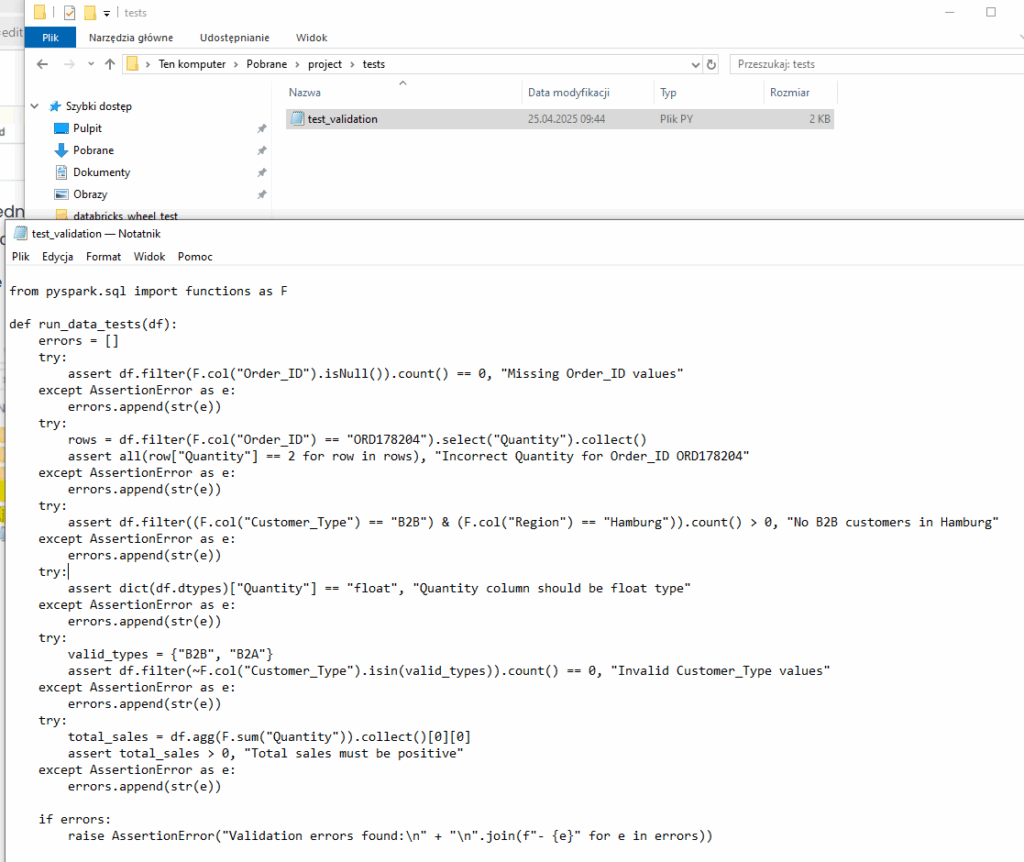
Co do naszego projektu, to testy jednostkowe najlepiej jednak wykonywać przed wrzuceniem na joba. W tym celu tworzymy folder tests z kodem do testów, który uruchamiamy lokalnie np. biblioteką pytest.
Dobrą praktyką jest także dodanie pliku requiments.txt , w którym dodajemy wymagane biblioteki do działania naszych kodów: