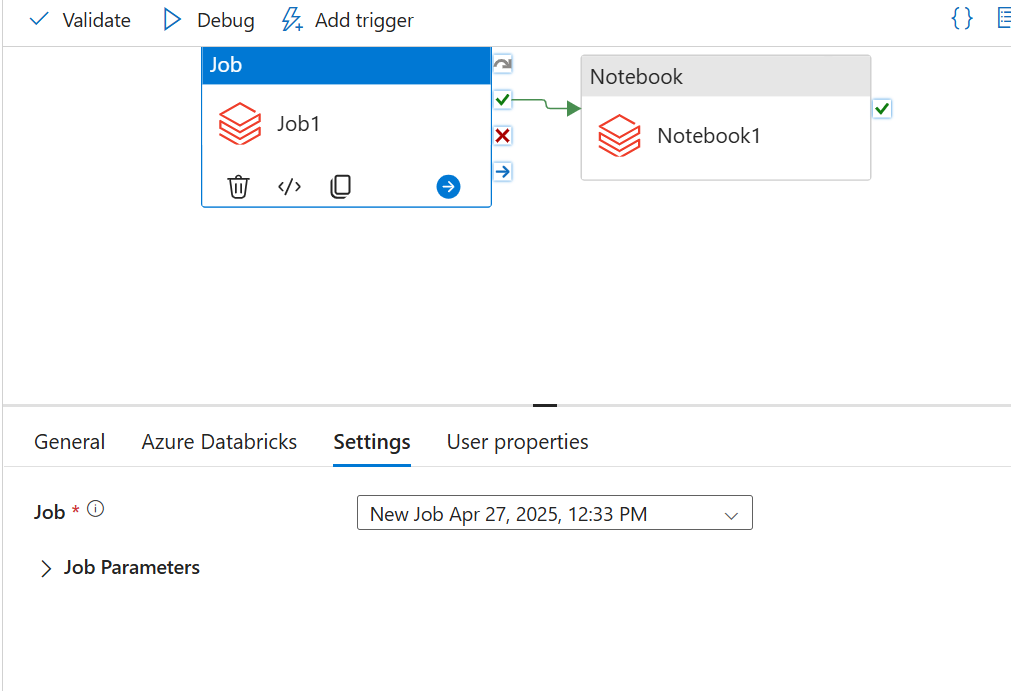
Jedną z funkcjonalności ADF jest dodanie notebooka lub joba Databricks jako części pipeline.
Wielką zaletą tego rozwiązania jest możliwość stworzenia pełnego potoku ETL w jednym pipeline. Możemy np. najpierw pobrać dane z SFTP, plików Excel od użytkowników czy API i potem uruchomić na tych danych joba w Databricks i za pomocą Azure Functions wysłać maila do odbiorców z wynikami. Wszystko mamy zcentralizowane i w jednym miejscu, do tego w intuicyjnym GUI.
Stwórzmy więc prosty pipeline, który wywołuje najpierw joba Databricks, a potem notebooka:
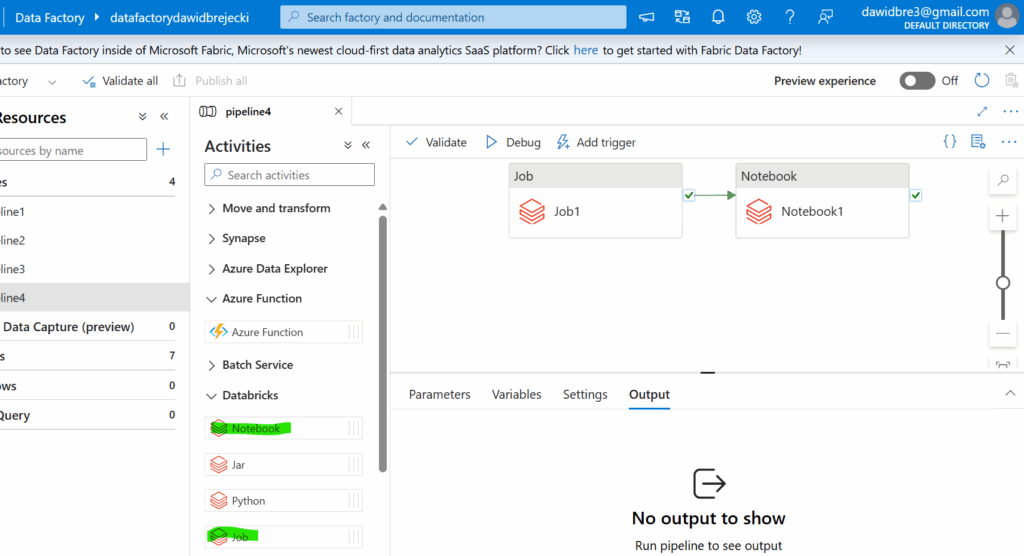
Tworzymy linked service do workspace w Databricks w którym mamy nasze joby i notebooki:
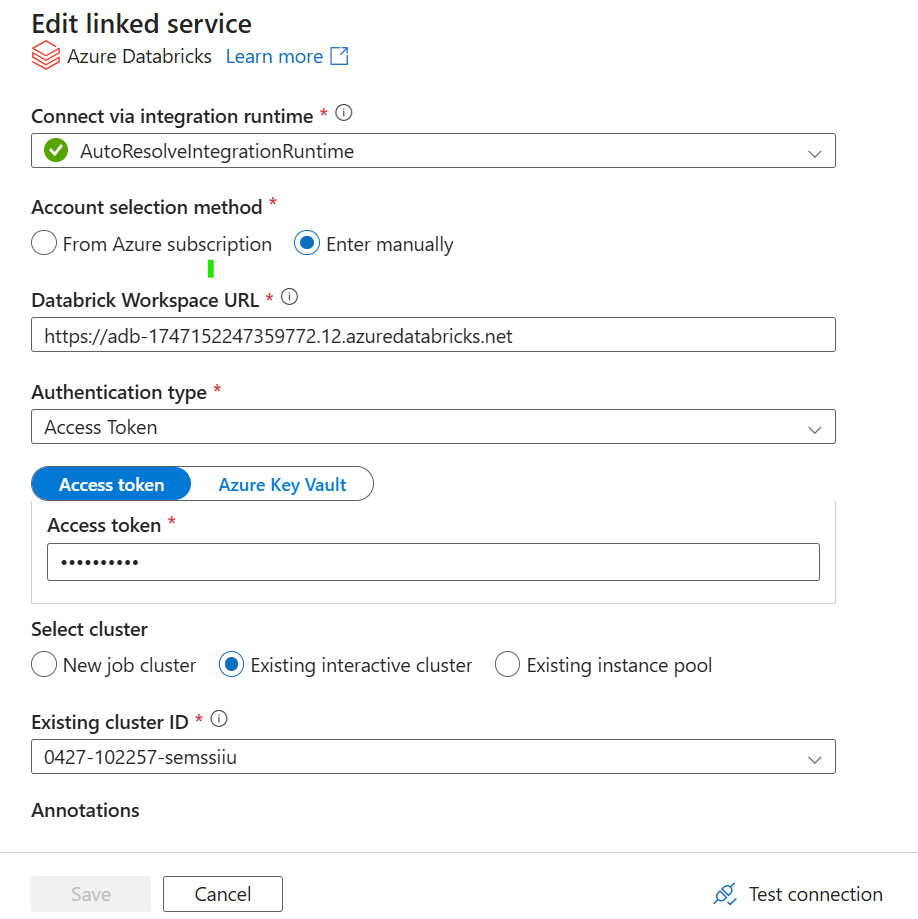
Jako account selection method możemy wybrać „from Azure subscription” – wtedy automatycznie pojawią się nam dostępne workspace lub wybieramy „Enter manually” i kopiujemy adres URL naszego workspace widocznego po otwarciu Databricks:

W authentication type wybieramy Managed Identity jeśli mamy w posiadaniu Access Connector do Databricks lub Access Token. Access Token generujemy w ustawieniach:
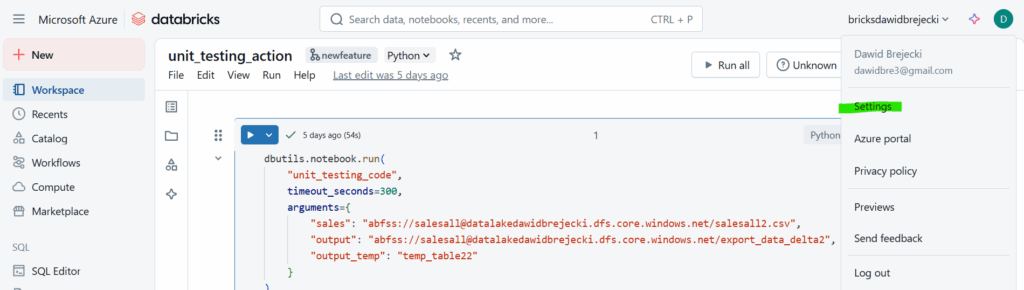
Developer – Manage – Generate New Token
Wklejamy go i gotowe. Musimy jeszcze wybrać klaster. Albo tworzymy nowy albo wybieramy któryś z utworzonych już w Databricks.
Joby i notebooki wybieramy prosto z list rozwijanej: