Jednym ze sposobów orkiestracji kodów napisanych w Databricks jest wywołanie jednego notebooka w drugim. Dzięki temu w zalezności od jego outputu możemy poprzez funkcje warunkowe kierować dalszym zachowaniem kodu. Jak to zrobić?
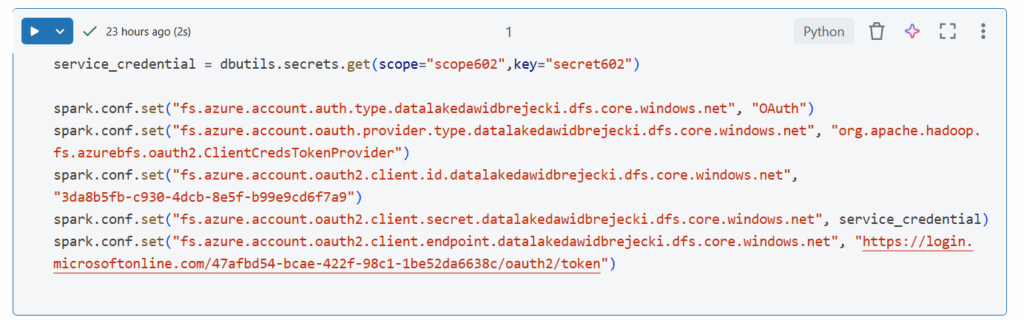
Załóżmy że chcemy wywołać następujący notebook zawierający konfigurację z połączeniem do Data Lake:
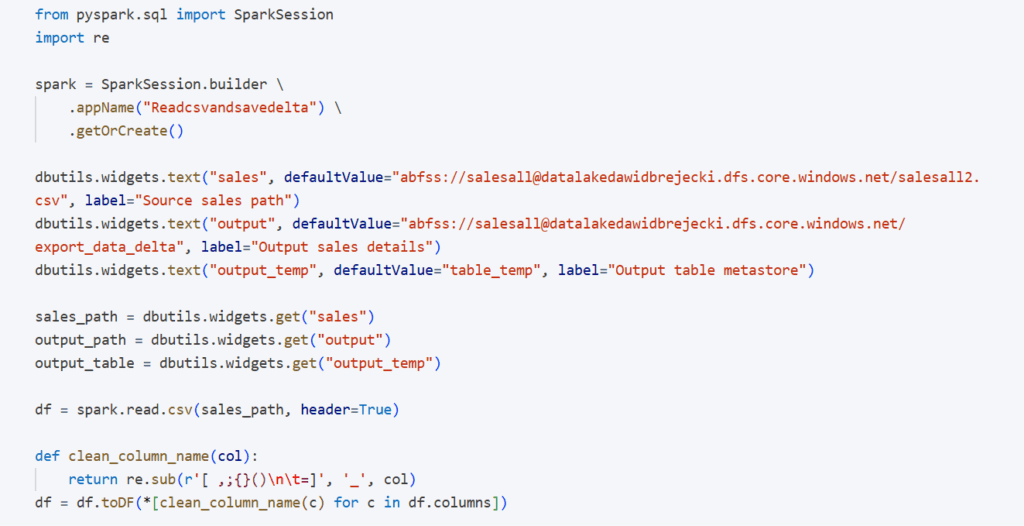
Przede wszystkim chcemy aby ten notebook był uniwersalny, byśmy mogli go wywoływać dla różnych danych i zapisywać różne outputy. Trzeba więc nadać parametr, który będziemy przekazywać, wywołując notebooka. Parametry w databricks nadajemy poprzez bibliotekę dbutils.widgets. Jako parametr ustawiamy dane wejściowe, dane wyjściowe w formacie Delta, oraz dane wyjściowe w postaci tabeli w metakatalogu. Dodatkowo poprzez funkcję clean_column_name pozbywamy się ew. znaków zabronionych, aby zwiększyć uniwersalność kodu.
Wczytane dane zapisujemy do Delty oraz katalogu:

Notebook wywoływany jest skończony. Spójrzmy teraz na notebooka wywołującego:
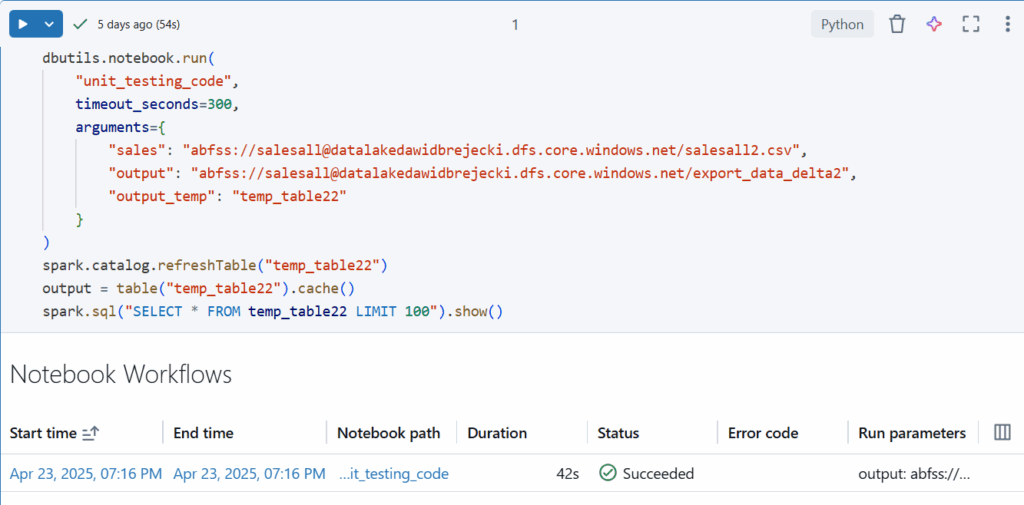
Przekazujemy w nim nazwę notebooka wywoływanego (lub pełną ścieżkę jeśli jest w innej lokalizacji), czas odpowiedzi oraz argumenty za pomocą dbutils.notebook.run. Możemy teraz w pełni korzystać z outputów lub wywołanych danych w obecnym notebooku 🙂