W poprzednim wpisie dowiedzieliśmy się, że największy wpływ na obniżenie wydajności raportu, mają kolumny o wysokiej kardynalności i niskiej powtarzalności.
Sposoby na zmniejszenie kardynalności:
- podobnie jak w przypadku zapytań SQL, najlepszym sposobem jest nieimportowanie niepotrzebnych kolumn. Liczbę kolumn możemy zmniejszyć w zapytaniu SQL-owym wysyłanym z poziomu Power BI do bazy klikając w „opcje zaawansowane”
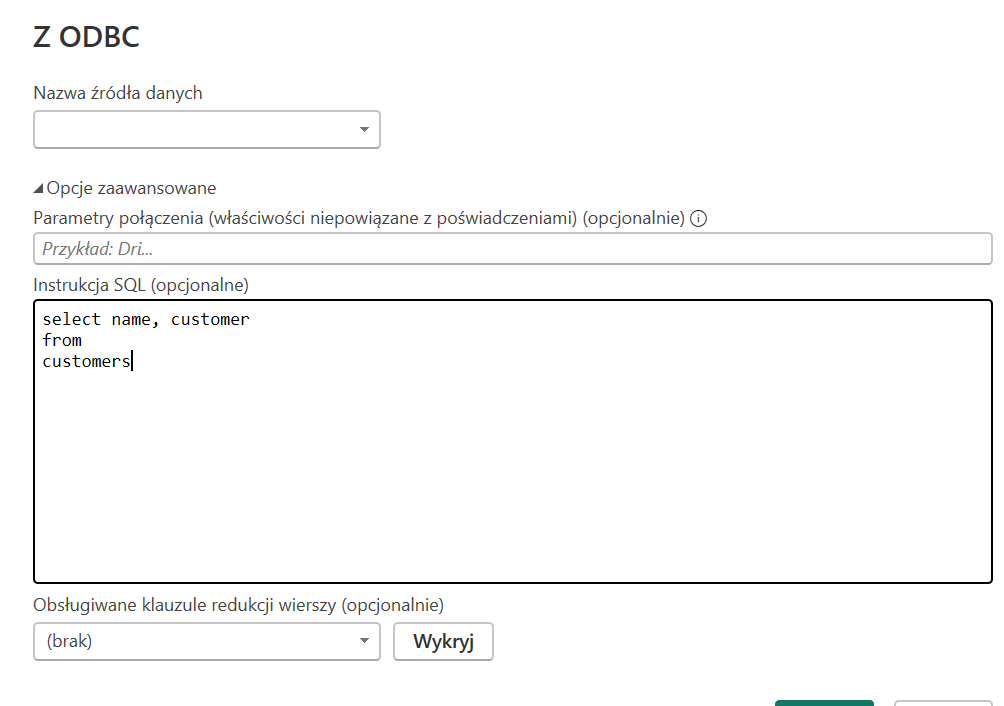
Jeżeli mamy dane załadowane do Power Query – tam usuwamy niepotrzebne kolumny. Ograniczanie liczby kolumn powinno być zawsze w tej kolejności: zapytanie do źródła danych – Power Query – model w DAX
- zmniejszenie liczby dziesiętnej np. z 19.23345 na 19.23. Dzięki temu liczba unikatowych wartości będzie znacznie mniejsza
- usunięcie kolumn typu sales_id, jeśli nie są używane. Kolumny klucza zawierają mnóstwo unikatowych wartości, których nie sposób skompresować. Często w tabeli faktów np. Sales, kolumna sales_id jest niepotrzebna i należy ją usunąć, tak samo jak inne podobne kolumny w następnych tabelach, które nie są używane do tworzenia relacji
- podział lub ograniczenie kolumny datetime. Kolumny typu datetime są niezwykle obciążające dla modelu. Same daty są dużo bardziej powtarzalne. Jeżeli nie potrzebujemy czasu – pobieramy tylko datę odpowiednią funkcją w zapytaniu SQL lub zamianą na typ date w Power Query lub funkcją Extract w Power Query. Jeżeli potrzebujemy informacji o czasie – pobieramy dwie kolumny osobno w zapytaniu SQL lub w Power Query dzielimy kolumnę funkcją Split by Delimiter
- wspomniany podział kolumn można zastosować dla innych kolumn modelu. Jeżeli np. w kolumnie tekstowej pierwszy człon np. Kwota_xxx powtarza się w wielu wierszach, warto taki podział wykonać.
- zaokrąglenie kolumny czasu – podobnie jak w przypadku liczb dziesiętnych, rzadko dla potrzeby raportowania potrzebujemy bardzo wysokiej dokładności
- użycie agregacji – tam gdzie to możliwe, stosujemy na poziomie Power Query. Posiadamy np. wiele transakcji z jednego dnia – możemy pogrupować wartości sprzedaży według dni. Zmniejszy to i kardynalność i liczbę wierszy w modelu.
Zwiększenie powtarzalności w kolumnie
- wybieramy najbardziej „trudną” kolumnę do skompresowania i sortujemy.