Tworzymy sesję Sparka i ładujemy dane z Bloba Azure
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler, StandardScaler
import xgboost as xgb
import pandas as pd
from collections import Counter
storage_account_name = "blobdawidbrejecki"
container_name = "xgboost"
account_key = ""
spark = SparkSession.builder.appName("XGBoostClassification").getOrCreate()
spark.conf.set(
f"fs.azure.account.key.{storage_account_name}.blob.core.windows.net",
account_key
)
data = spark.read.csv(
f"wasbs://{container_name}@{storage_account_name}.blob.core.windows.net/wsad_z1.csv", header=True, sep=";",
inferSchema=True
)
Zamiana przecinkow na kropki i zmiana typu danych
data = data.select([regexp_replace(col(c), ",", ".").alias(c) for c in data.columns])
data = data.select([col(c).cast("double").alias(c) for c in data.columns])
Zamiana nulli na 0
data = data.fillna(0)
Macierz korelacji i usunięcie skorelowanych kolumn
corr_matrix = pd.DataFrame(correlation_matrix.toArray(), columns=numeric_cols, index=numeric_cols)
print(corr_matrix)
columns_to_drop = ['VAR9','VAR10','VAR11','VAR12','VAR13','VAR14','VAR26','VAR27',"VAR28", "VAR2", "VAR5", "VAR4", "VAR15", "VAR17", "VAR6","VAR20", "VAR8"]
df=data
Pobieramy nazwy wszystkich zmiennych objasniajacych i łączymy w jeden wektor
columns = [col for col in df.columns]
feature_cols = [col for col in df.columns if col != 'docelowa']
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df = assembler.transform(df)
Standaryzujemy dane
scaler = StandardScaler(inputCol="features", outputCol="scaled_features", withStd=True, withMean=False)
df_scaled = scaler.fit(df).transform(df)
Dzielimy dane na zbiór testowy i treningowy
train_data, test_data = df_scaled.randomSplit([0.8, 0.2], seed=1234)
Nasz zbiór ma niezbalansowaną zmienną objaśnianą. Dlatego redukujemy ten problem używając parametru scale_pos_weight w XGBoost
label_counts = Counter(train_data.select("docelowa").toPandas()["docelowa"])
num_pos = label_counts[1]
num_neg = label_counts[0]
scale_pos_weight = num_neg / num_pos
Przygotowujemy dane do trenowania
train_data_pd = train_data.select("docelowa", "scaled_features").toPandas()
X_train = [x.toArray() for x in train_data_pd["scaled_features"]]
y_train = train_data_pd["docelowa"].values
Trenujemy
dtrain = xgb.DMatrix(X_train, label=y_train)
params = {
'objective': 'binary:logistic',
'max_depth': 3,
'eta': 0.1,
'eval_metric': 'logloss',
'scale_pos_weight': scale_pos_weight
}
model = xgb.train(params, dtrain, num_boost_round=10)
Obliczamy accuracy i tworzymy confusion matrix
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
y_pred = [1 if x > 0.5 else 0 for x in y_pred] # Zamiana na 0 lub 1 na podstawie progu 0.5
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["0", "1"], yticklabels=["0", "1"])
plt.xlabel("Przewidywane")
plt.ylabel("Rzeczywiste")
plt.title("Macierz Pomyłek")
plt.show()
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
Wykres ważności zmiennych objaśniających modelu:
original_columns = feature_cols
importances = model.get_score(importance_type='weight')
sorted_importances = sorted(importances.items(), key=lambda x: x[1], reverse=True)
print("Ważność cech:")
for feature, importance in sorted_importances:
feature_index = int(feature[1:])
print(f"Cecha: {original_columns[feature_index]} - Ważność: {importance}")
sorted_columns = [original_columns[int(feature[1:])] for feature, _ in sorted_importances]
importance_values = [importance for _, importance in sorted_importances]
plt.figure(figsize=(10, 6))
plt.barh(sorted_columns, importance_values)
plt.xlabel('Ważność')
plt.ylabel('Cecha')
plt.title('Ważność cech w modelu XGBoost')
plt.show()
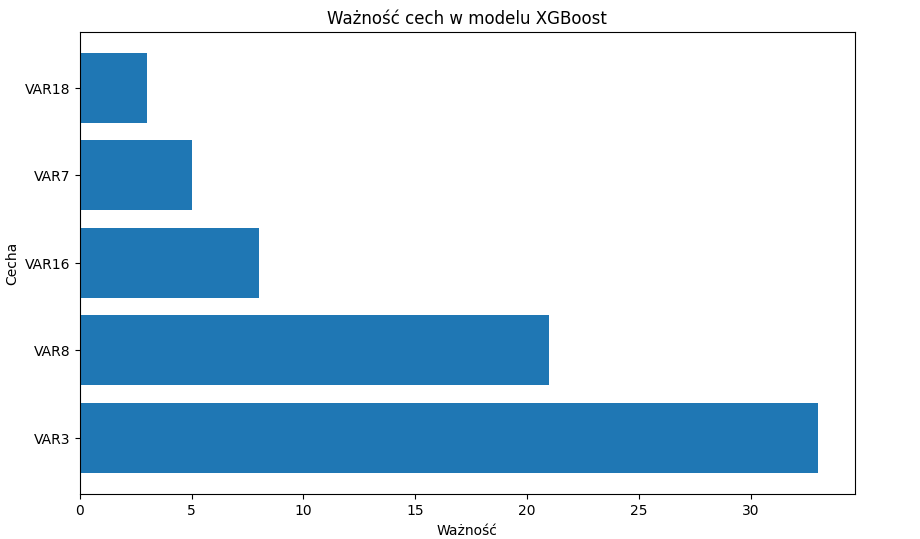
Dobrą praktyką jest usuwanie zmiennych najmniej znaczących i obserwowanie zmianę accuracy. Jeżeli jest ona nieznaczna, usuwamy je. Im mniej zmiennych w modelu tym lepiej, model lepiej będzie klasyfikował nowe przypadki.
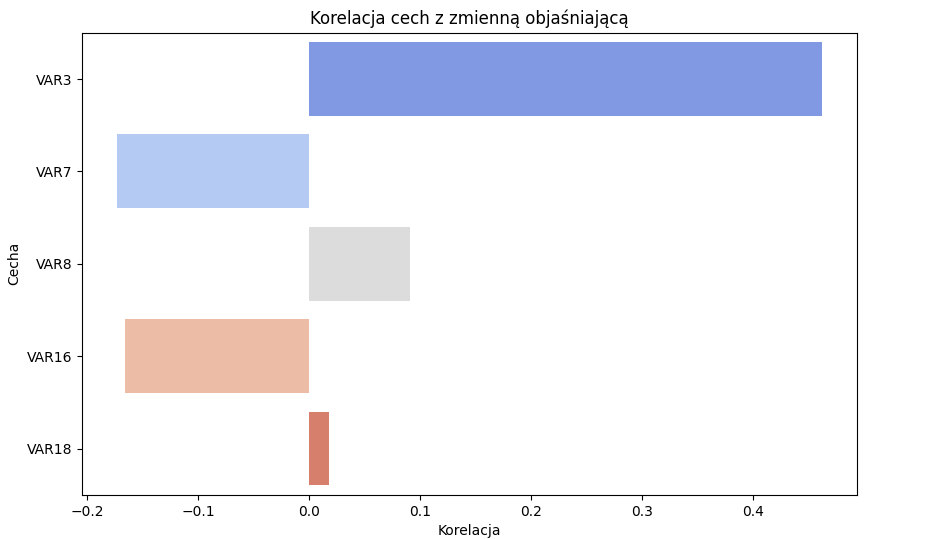
Wykres korelacji zmiennych mówi nam o kierunku i sile korelacji:
correlations = {}
for feature in feature_cols:
correlation = df.stat.corr(feature, 'docelowa')
correlations[feature] = correlation
correlation_df = pd.DataFrame(list(correlations.items()), columns=['Feature', 'Correlation'])
plt.figure(figsize=(10, 6))
sns.barplot(x='Correlation', y='Feature', data=correlation_df, palette='coolwarm')
plt.title('Korelacja cech z zmienną objaśniającą')
plt.xlabel('Korelacja')
plt.ylabel('Cecha')
plt.show()
Zapis modelu do pliku
model.save_model('modelz.bin')
Ładowanie modelu i predykcja na nowych danych
import xgboost as xgb
model = xgb.Booster()
model.load_model('sciezka/modelz.bin')
import pandas as pd
X_test['VAR3'] = pd.to_numeric(X_test['VAR3'], errors='coerce')
X_test['VAR16'] = pd.to_numeric(X_test['VAR16'], errors='coerce')
X_test = X_test.fillna(0)
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
X_test['prediction'] = y_pred