Zajmijmy się teraz jak jedną z najprotszych (ale i najczęściej używanych operacji) jaką jest kopiowanie plików.
Business Case:
W kontenerze usługi Blob Storage umieszczonych jest większa liczba plików .csv. Naszym zadaniem jest utworzyć plik zbiorczy zawierający kontent ze wszystkich tych plików i wysłać na lokalizację w Azure Data Lake. W naszym blobie mamy trzy pliki do skopiowania:
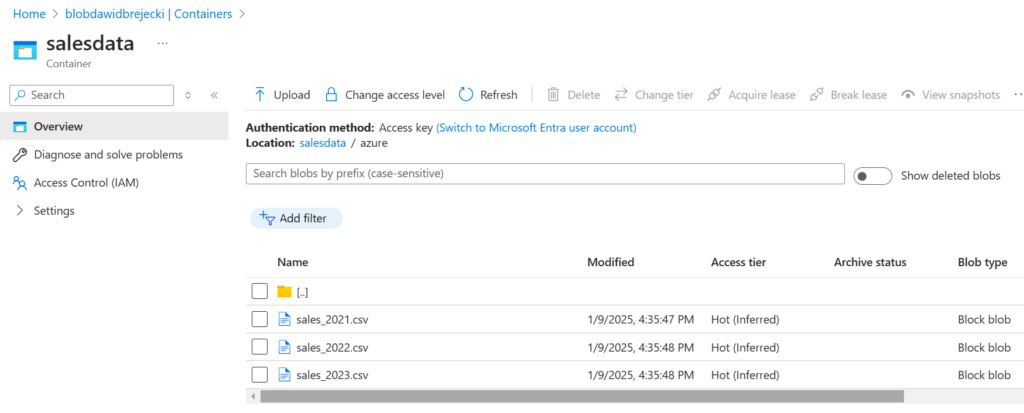
Tworzenie Bloba i Data Lake jest tak proste że nie wymaga opisu.
Najpierw utworzymy linked service dla Bloba i Data Lake:
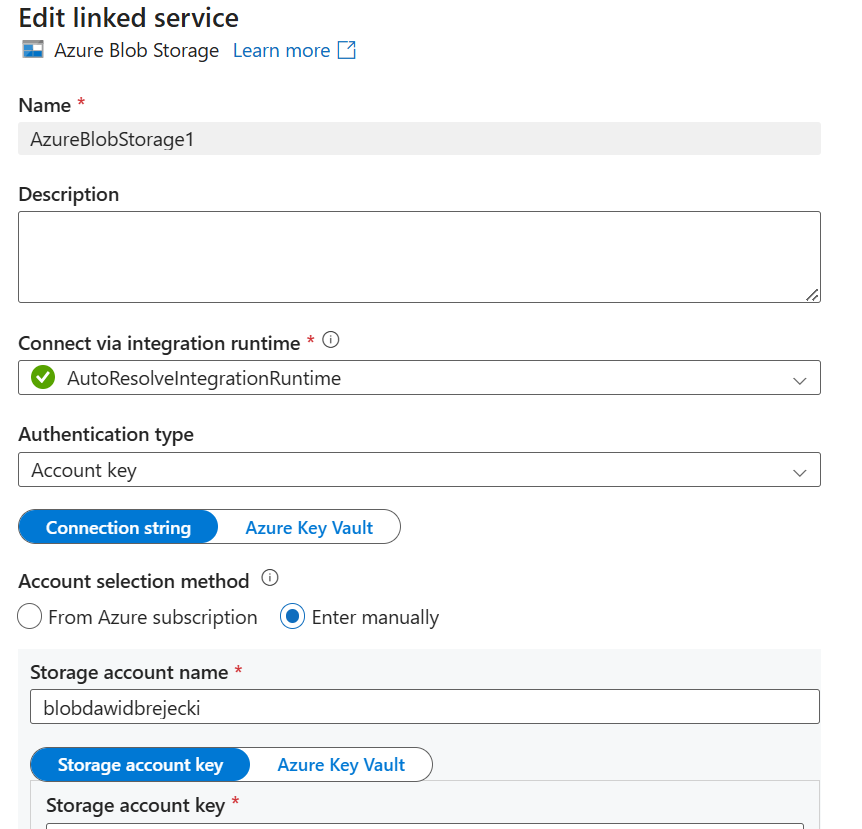
Jako integration runtime wybieramy AutoResolve – domyślnie dla usług w Azure.
Następnie tworzymy dataset dla źródła danych. Tworząc dataset wybieramy Azure Blob Storage, a następnie format plików jakie będziemy pobierać – csv. Następnie wybieramy nasz linked service, nazwę naszego bloba i przechodzimy do konkretnego pliku lub zaznaczamy cały folder. W naszym przypadku za jednym razem chcemy pobrać wszystkie pliki, więc zaznaczamy cały folder. Powinien pokazać się nam następujący widok:
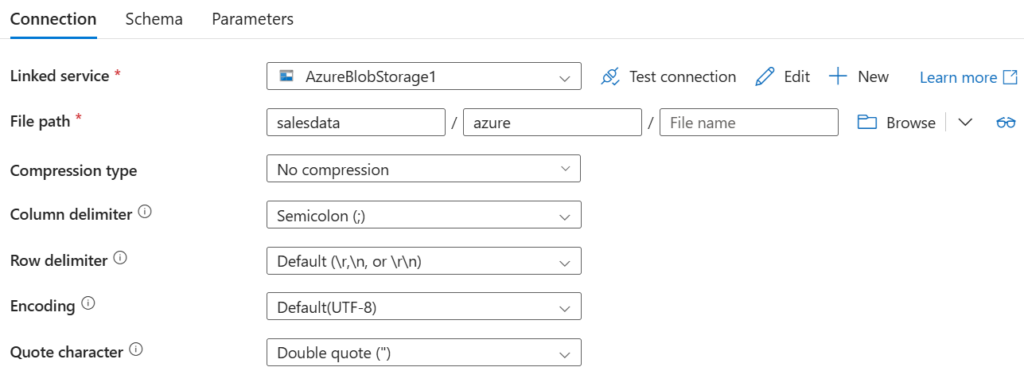
Nie wypełniamy pola File name. Zaznaczamy prawidłowy delimiter oraz kodowanie.
Następnie tworzymy dataset dla danych docelowych. Zaznaczamy Azure Data Lake, plik csv jako format naszych danych docelowych i folder w którym chcemy umieścić nasz plik zbiorczy
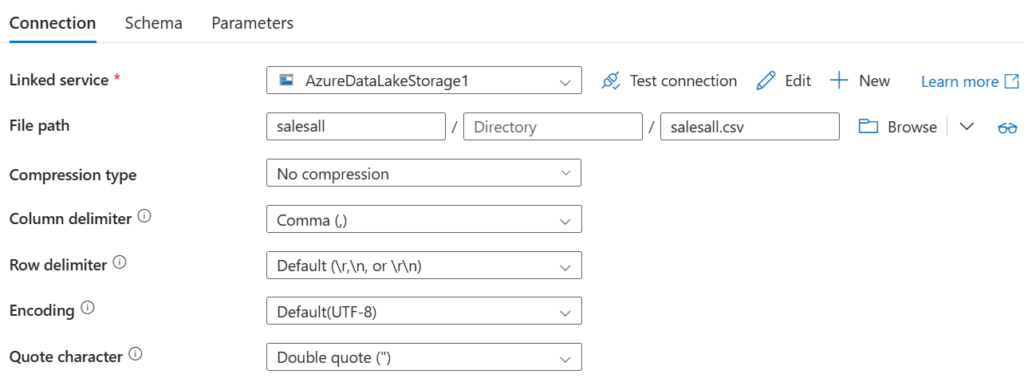
Plik zbiorczy jest jednoznaczny, więc wpisujemy jego nazwę w File Path, co ważne z rozszerzeniem. Robimy to pomimo tego że ten plik jeszcze nie istnieje.
W tej chwili możnaby pomyśleć czy nie wygodniej byłoby zapisać plik zbiorczy w excelu. Azure Data Factory nie obsługuje jednak formatu excela jako datasetu docelowego. Może z excela tylko odczytać. Można to obejść pisząc kod w Sparku lub używając Azure Logic Functions, ale nie to jest celem tego artykułu.
Mamy utworzony linked service i datasets, więc możemy utworzyć pipeline i wybrać z Actions – copy data
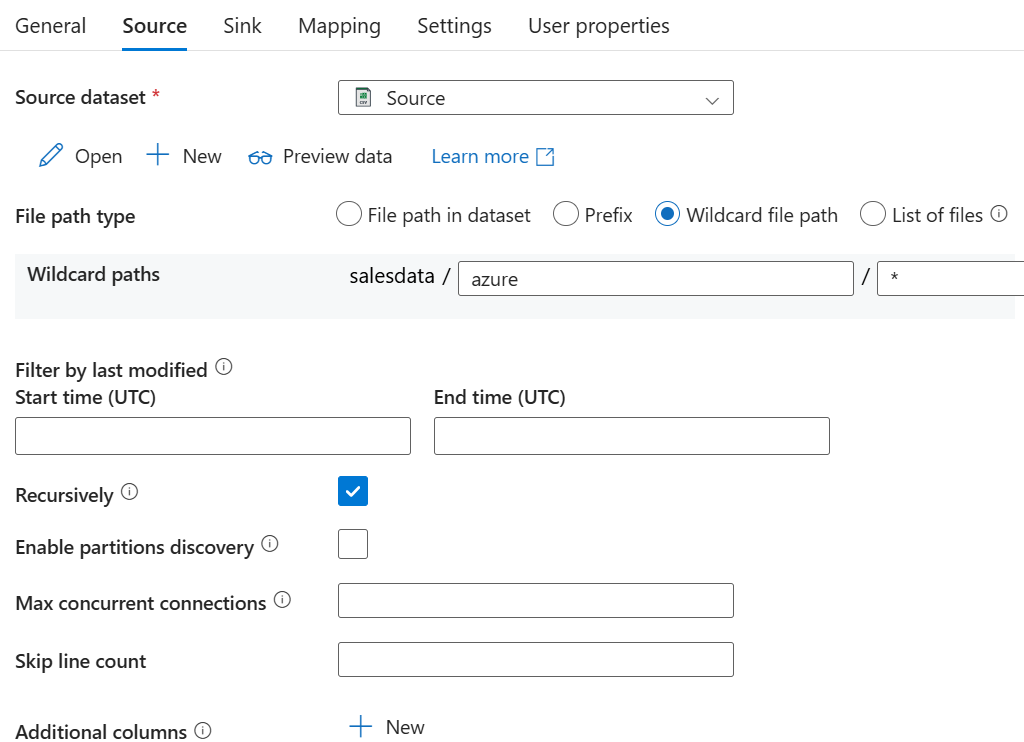
Najważniejsze dla nas zakładki to Source i Sink (docelowy plik).
W File path type zaznaczamy Wildcard file path, ponieważ chcemy pobrać wszystkie pliki. Gdybyśmy chcieli pobrać konkretny plik, zaznaczylibyśmy File path in dataset. Jeżeli mielibyśmy utworzoną wcześ niej listę plików – List of files. Prefix – jeśli chcielibyśmy pobrać tylko pliki z nazwą rozpoczynającą się od wybranego ciągu znaków.
Opcję Recursively zaznaczamy jeśli chcemy aby program przeszukał nam także podfoldery z naszego kontenera w poszukiwaniu plików .csv.
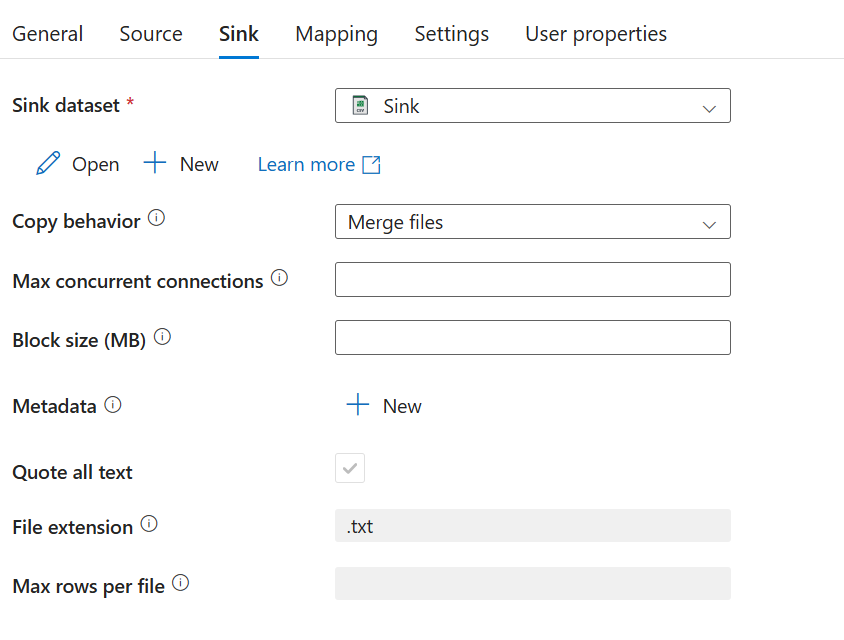
W zakładce Sink zaznaczamy utworzony wcześniej dataset i copy behavior. Zaznaczamy tu Merge files aby połączyć wszystkie pliki w jeden. Inne opcje – Flatten hierarchy oznacza że w przypadku kopiowania wielu plików ze źródła które zawiera podfoldery, w folderze docelowym nie będzie już podfolderowych tylko „spłaszczona” hierarchia plików. Opcja preserve hierarchy zachowuje podfoldery.
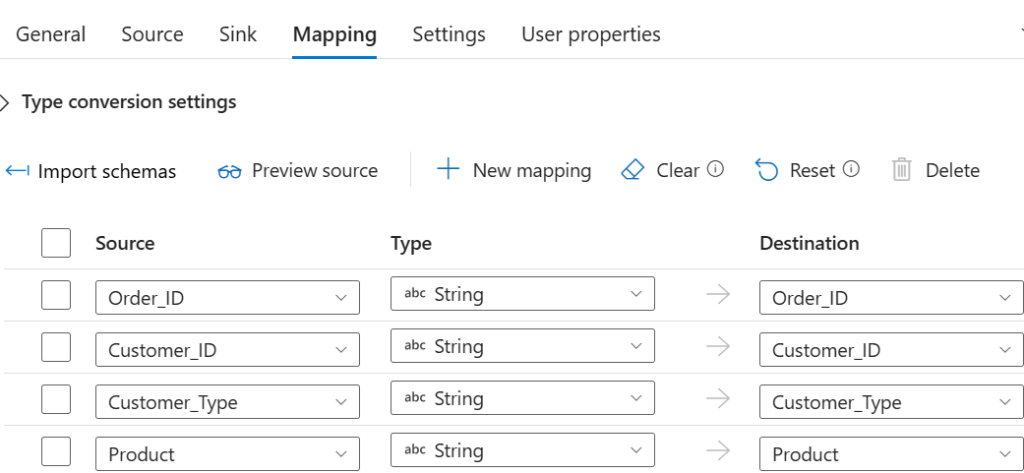
W zakładce Mapping, po kliknięciu opcji Import schemas możemy zmienić typ danych, dodać i odjąć kolumny które miałyby się pojawić w pliku docelowym. W naszym przypadku nie zmieniamy nic.
Gotowe. Klikamy Debug i pipeline jest uruchomiony.