Dobre praktyki inżyniera/analityka danych obejmują dbałość o jakość danych, ich spójność oraz bezpieczeństwo.
Jakość danych
Dbałość o jakość danych obejmuje sprawdzanie duplikatów, typów danych, nulli, obecności wartości w określonym zakresie, posiadania określonej postaci (np. nr telefonu xxx-xxx-xxx).
Dobrą praktyką (i zdecydowanie zalecaną produkcyjnie) jest umieszczenie w jednej klasie/module/pliku.py funkcji wywoływanych w osobnym pliku.
Utwórzmy zatem klasę z pierwszą definicją funkcji sprawdzającej braki danych:

I jej wywołanie:
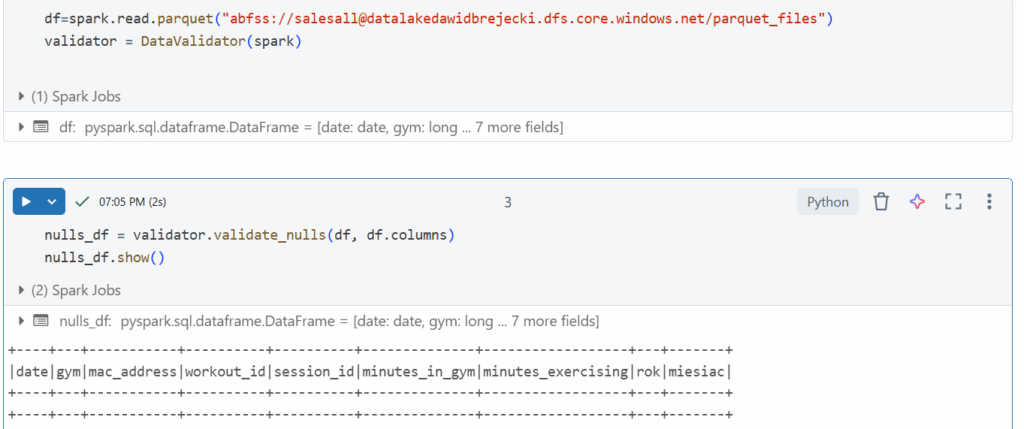
Sprawdzenie duplikatów po wybranych kolumnach oraz po całym zbiorze:

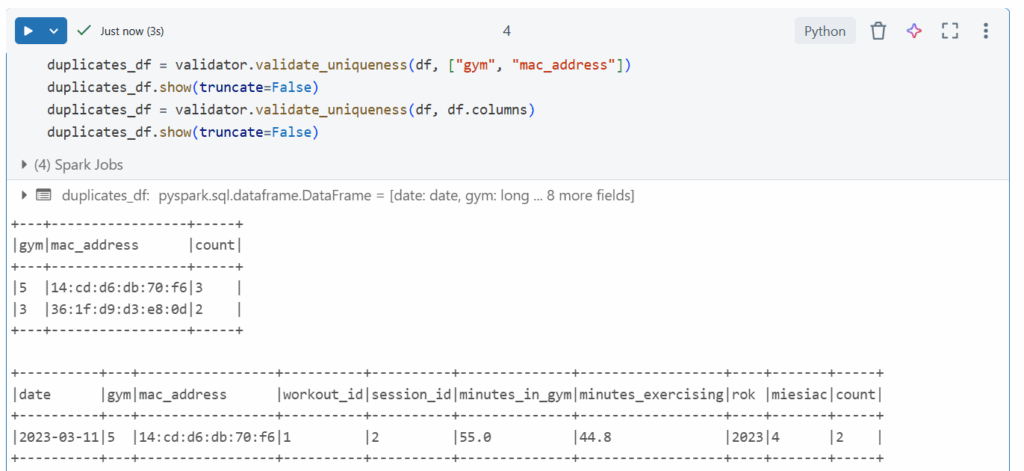
Sprawdzanie określonej postaci danych np. dla mac_address xx:xx:xx:xx:xx:xx

Typy danych w kolumnach:


Spójność (integralność danych) obejmuje m.in. sprawdzanie czy występują osierocone rekordy w jednej tabeli
Sprawdzamy czy dla każdego usera w jednej tabeli występuje rekord w innej:


Dbałość o bezpieczeństwo to anonimizacja lub pomijanie niektórych danych które nie powinny być widoczne dla danej osoby (grupy osób)
Np. funkcja anonimizująca pierwszą część członu adresu mailowego:

Co jak znajdziemy dane niepodpowiadające naszym standardom jakości
W zależności od wymagań użytkowników, takie dane najczęściej pomijamy w dalszym procesowaniu i możemy zapisać w jakiejś lokalizacji do sprawdzenia przez źródło danych. Można stosować obejścia (np. wymuszanie danego typu kolumny), ale najczęściej naprawia się dane u źródła. Przykład kodu zapisującego do określonej lokalizacji błędne wiersze (zduplikowane) i zwracającego ramkę danych bez dubli:

Podsumowanie
Wykorzystane powyżej funkcje możemy wykorzystać adhocowo w notebookach lub przeprowadzać testy jednostkowe. Jak opakować funkcje w moduły i przeprowadzać w pełni zautomatyzowane testy, opisane jest w następnych artykułach.