DBFS to lokalny system plików Databricks. Używanie jego zwiększa prostotę pisania kodu i umożliwia przechowywanie plików z wielu różnych źródeł
Tworzenie mount point do Data Lake
Mount point umożliwia zamontowanie kontenera Data Lake do katalogu DBFS. Co ważne, jeżeli po zamontowaniu pojawią się nowe pliki lub obecne zostaną zmodyfikowane, pojawią się one w katalogu DBFS, ponieważ pliki fizycznie występują na storage.
Najpierw musimy utworzyć aplikację z odpowiednimi uprawnieniami. Jak ją zrobić, podane jest w artykule „Databricks – łączenie z danymi z Azure SQL Database i Azure Storage za pomocą Entra, hasła i loginu oraz Key Vault„. Tworzymy nową aplikację lub korzystamy z utworzonej wcześniej.
Uruchamiamy następujący kod i gotowe:
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "3da8b5fb-c930-4dcb-8e5f-b99e9cd6f7a9",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope="scope602",key="secret602"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/47afbd54-bcae-422f-98c1-1be52da6638c/oauth2/token" }
dbutils.fs.mount(
source = "abfss://salesall@datalakedawidbrejecki.dfs.core.windows.net/",
mount_point = "/mnt/sales",
extra_configs = configs)
Objaśnienia:
mount point – wpisujemy ścieżkę w jakiej zapisać odniesienie do kontenera. Jeśli nie istnieje, to nie problem
salesall – nazwa kontenera Data Lake
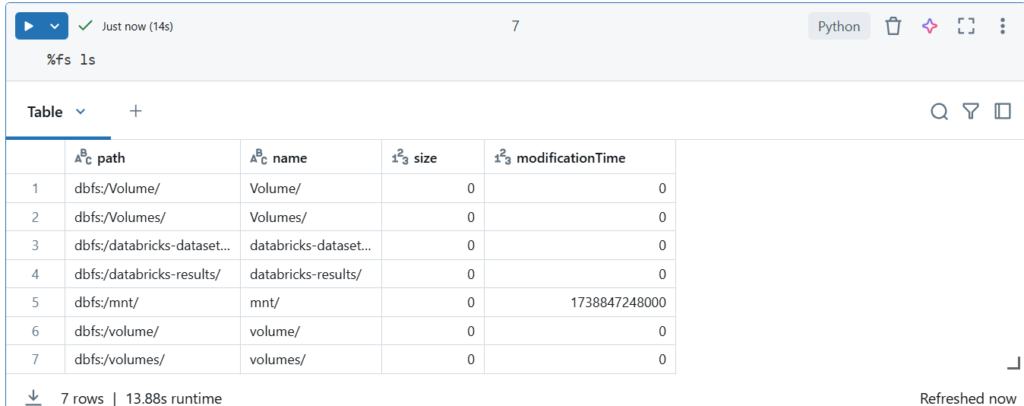
Lista wszystkich ścieżek DBFS:
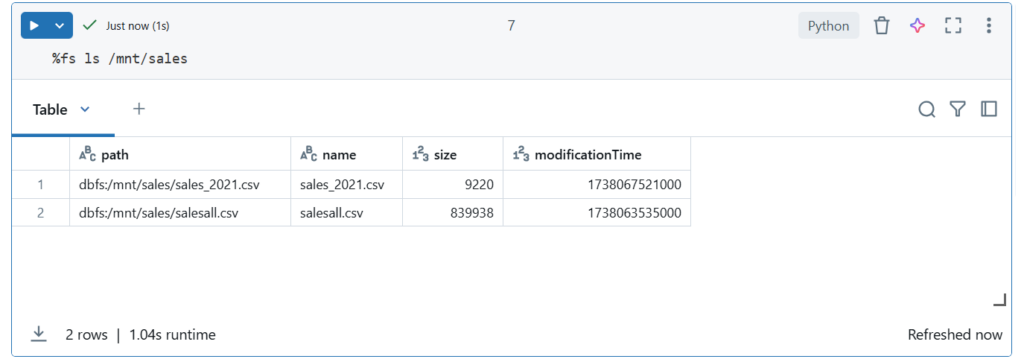
Co głębiej jest w naszym zamontowanym katalogu
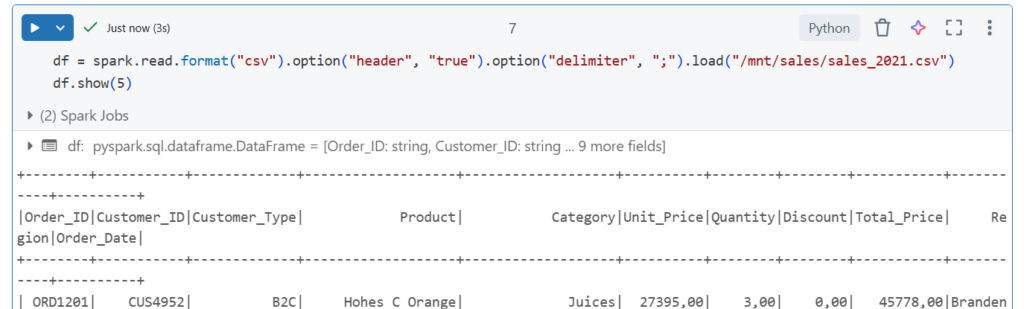
Odczyt pliku z katalogu DBFS
Zapis do katalogu

Zmiana nazwy zapisanego pliku

Usuwanie pliku

Zapis do formatu Delta Lake

Ładowanie wielu plików na raz
