Połączenie z Azure SQL Database – za pomocą loginu i hasła – bez użycia Azure Key Vault
Aby połączyć się z bazą Azure SQL za pomocą loginu i hasła, musimy podać w kodzie hasło do bazy, login do bazy, nazwę serwera (nie bazy) na którym nasza baza jest postawiona i nazwę bazy. Nazwy te możemy odczytać po zalogowaniu do bazy w portalu Azure
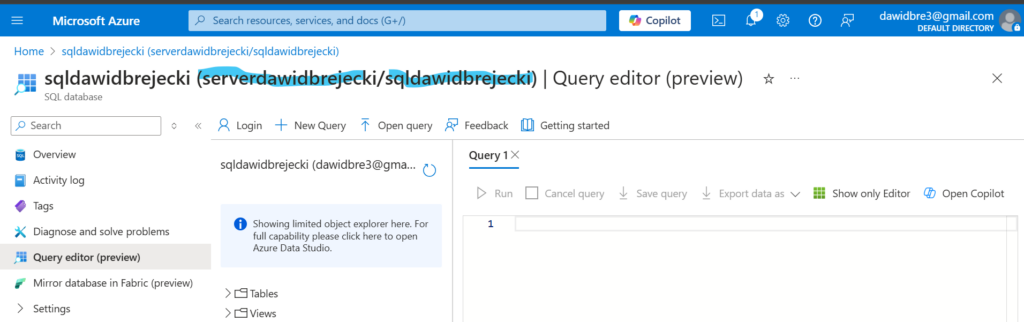
Kod do pobrania z bazy Azure SQL danych z tabeli Sales:
server_name = "serverdawidbrejecki.database.windows.net"
database_name = "sqldawidbrejecki"
username = "dawidbrejecki"
password = ""
jdbc_url = f"jdbc:sqlserver://{server_name}:1433;database={database_name}"
connection_properties = {
"user": username,
"password": password,
"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
query = "SELECT * FROM sales"
df = spark.read.jdbc(url=jdbc_url, table=f"({query}) as query", properties=connection_properties)
Do zmiennej query przypisujemy zapytanie SQL które wyciąga nam informacje z bazy. Może być ono bardziej skomplikowane i wyciągać informacje np z dwóch tabel z bazy np.
select order_date, customer_name from sales left join customers on sales.customer_id=customer.id
Podczas próby łączenia się z bazą może pojawić się błąd typu:

Oznacza to, że IP naszych zasobów Databricks jest blokowany przez serwer Azure SQL. Aby to naprawić trzeba najpierw poznać nasz adres (ze strony Databricks) lub za pomocą kodu:
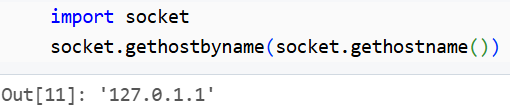
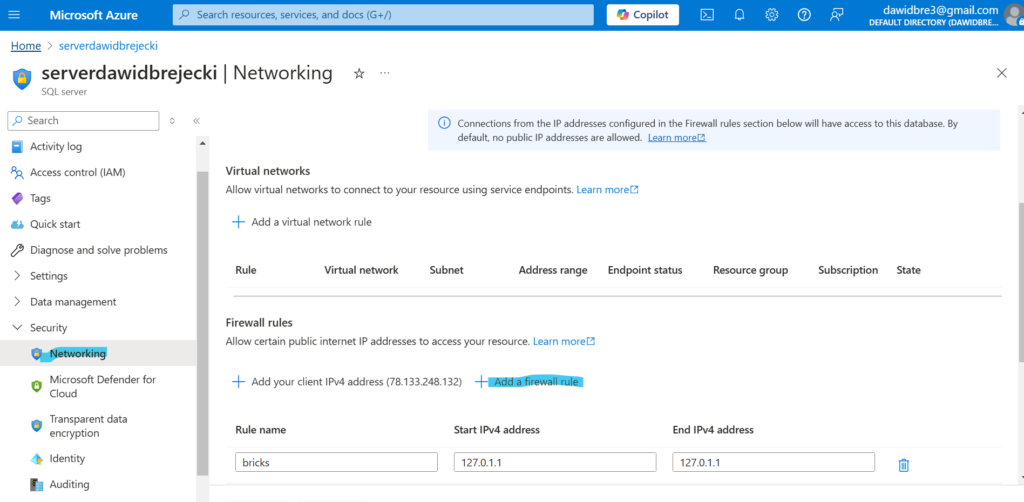
Uzyskany adres IP dodajemy do reguły firewalla naszego serwera Azure SQL:
Zapis do tabeli w Azure SQL Database
W kodzie musimy sprecyzować nazwę tabeli do jakiej zapisujemy – u nas do new_sales_data
df.write \
.format("jdbc") \
.option("url", jdbc_url) \
.option("dbtable", "new_sales_data") \
.option("user", jdbc_properties["user"]) \
.option("password", jdbc_properties["password"]) \
.option("driver", jdbc_properties["driver"]) \
.mode("append") \
.save()
Połączenie z Azure Blob Storage (analogicznie kroki wykonuje się dla Data Lake)
Pobieranie danych z Bloba jest mniej kłopotliwe:
storage_account_name = "blobdawidbrejecki"
container_name = "salesdata"
account_key = ""
spark.conf.set(
f"fs.azure.account.key.{storage_account_name}.blob.core.windows.net",
account_key
)
df = spark.read.csv(f"wasbs://{container_name}@{storage_account_name}.blob.core.windows.net/azure/sales_2021.csv", header=True)
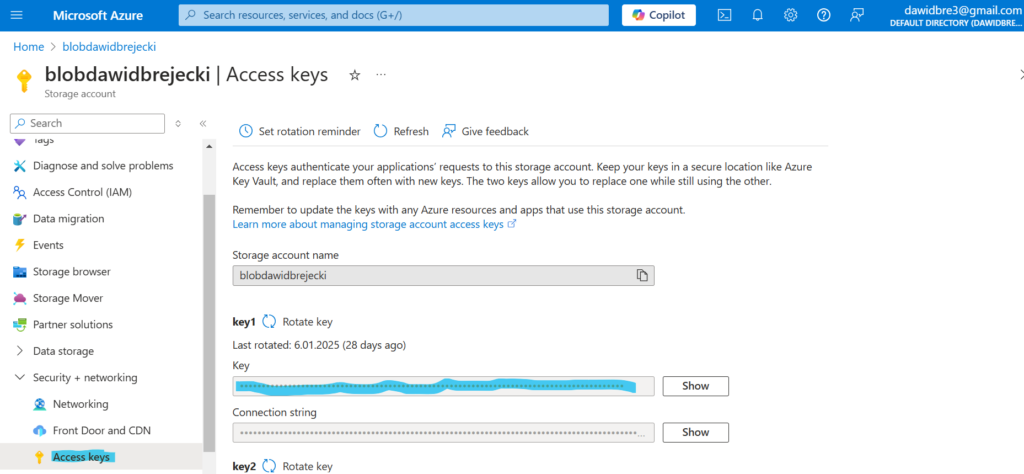
Jako account_key pobieramy wchodząc w zakładkę Access Keys naszego bloba i kopiujemy Key:
W kodzie wpisujemy także nazwę bloba, kontenera w którym jest nasz plik z danymi oraz pełną ścieżkę do pliku.
Zapis do pliku na Blob
df.write.mode("overwrite").option("header", "true").csv(f"wasbs://{container_name}@{storage_account_name}.blob.core.windows.net/output.csv")
Połączenie do Azure Data Lake za pomocą Microsoft Entra i Azure Key Vault
Kolejnym rodzajem połączenia do naszego storage jest zarejestrowanie aplikacji w Microsoft Entra, ukrycie jej secretu w Azure Key Vault, nadanie odpowiedniej roli Databricks i wykorzystanie secret codu w notebooku.
Aby utworzyć aplikację, wyszukujemy Microsoft Entra i klikamy:
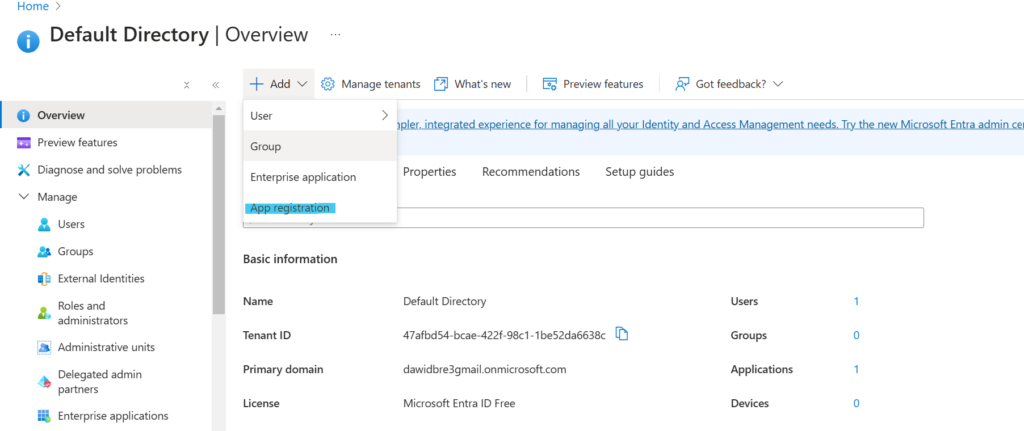
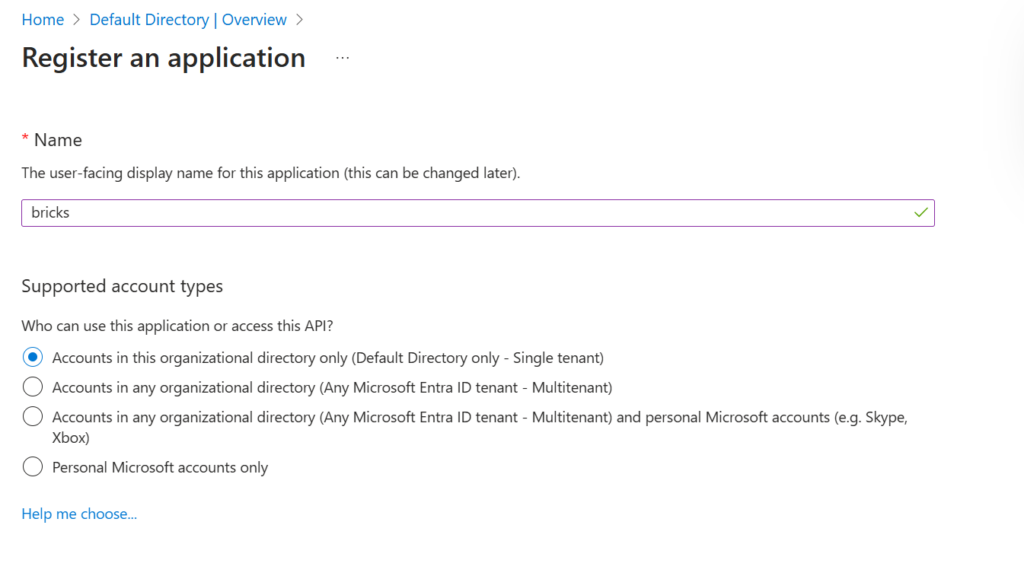
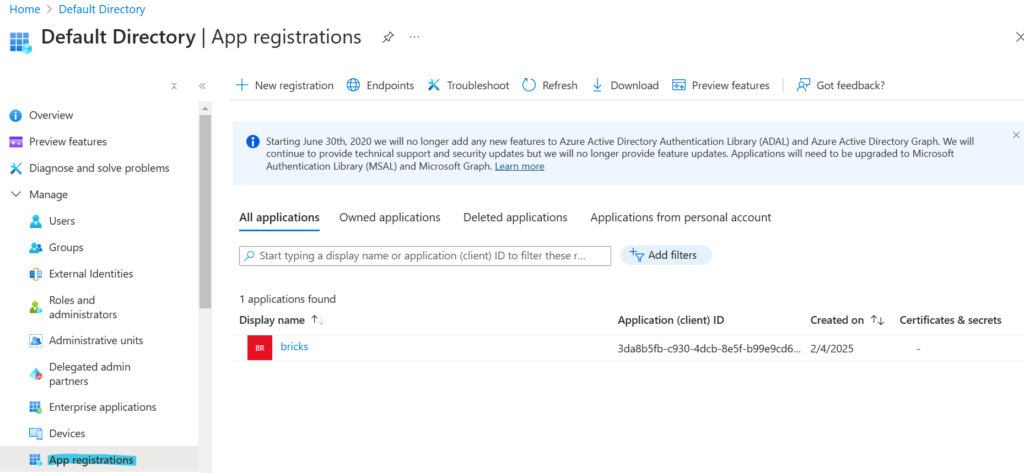
Po utworzeniu aplikacja będzie widoczna w App registrations
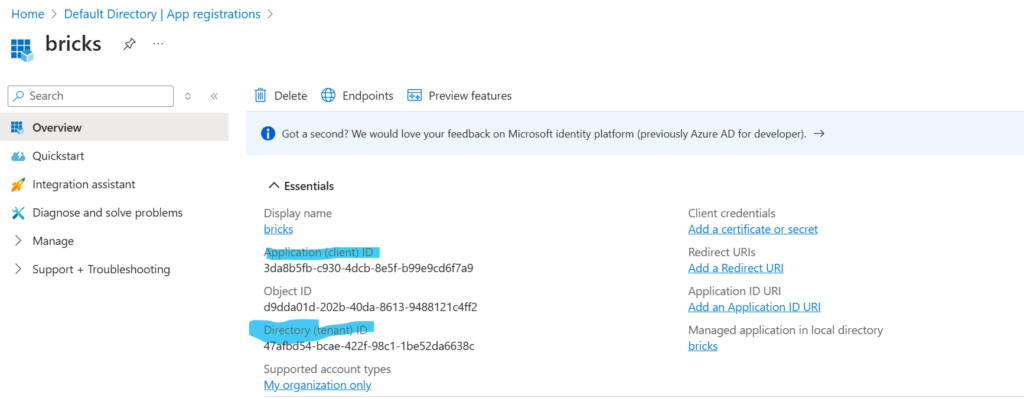
Klikamy na nią i spisujemy potrzebne nam później client_id oraz tenant_id
I tworzymy secret dla tej aplikacji:
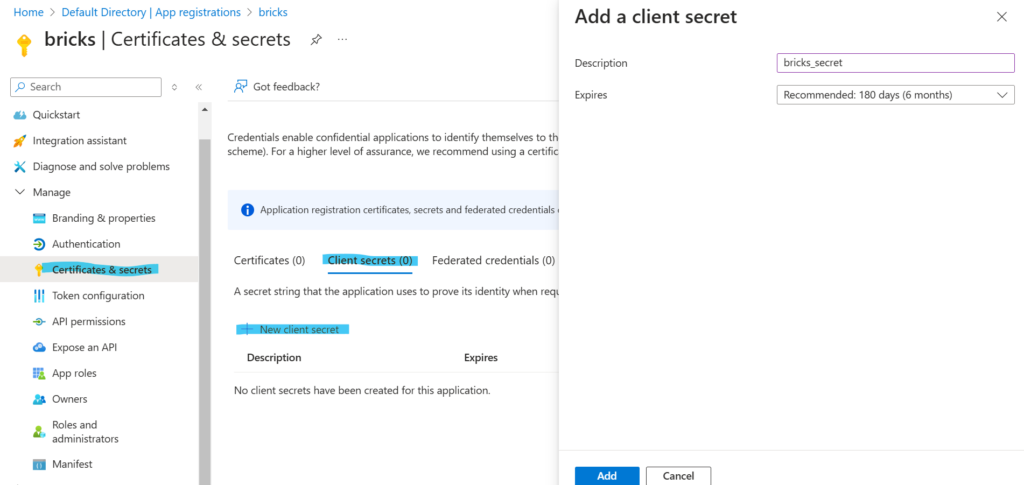
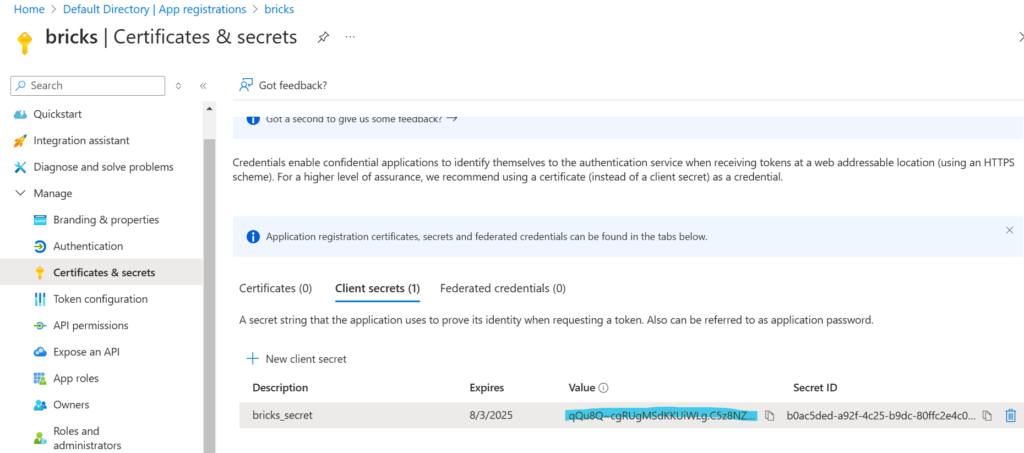
Spisujemy wartość Value
Teraz przechodzimy do naszego Data Lake. Tworzymy nową rolę IAM:
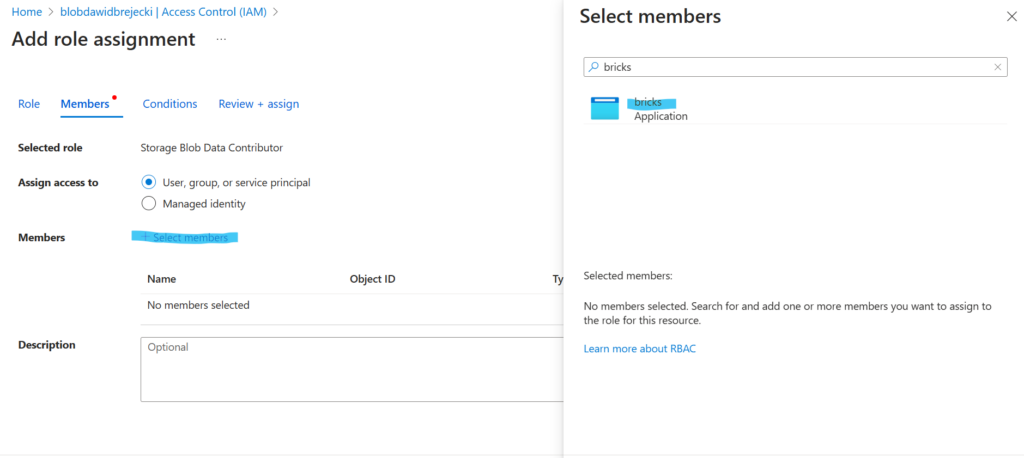
Szukam roli Storage Blob Data Contributor. Taka rola pozwoli nam zarówno na odczyt jak i zapis plików na storage

Teraz najważniejsza część: jako membera naszej roli wyszukujemy i zaznaczamy naszą utworzoną wcześniej aplikację
Aby nie pisać secretu tej aplikacji w formie jawnej, tworzymy Key Vault, by dodać do niego secret. Dzięki temu w kodzie Spark będziemy odwoływać się tylko do nazwy naszego secretu, nie jego wartości.
W Key Vault aby zacząć dodawać secrety musimy utworzyć rolę dla swojego konta jako Key Vault Secret Officer.
Następnie tworzymy rolę Key Vault Secrets User dla aplikacji AzureDatabricks, aby z jej poziomu można było pobierać secrety.
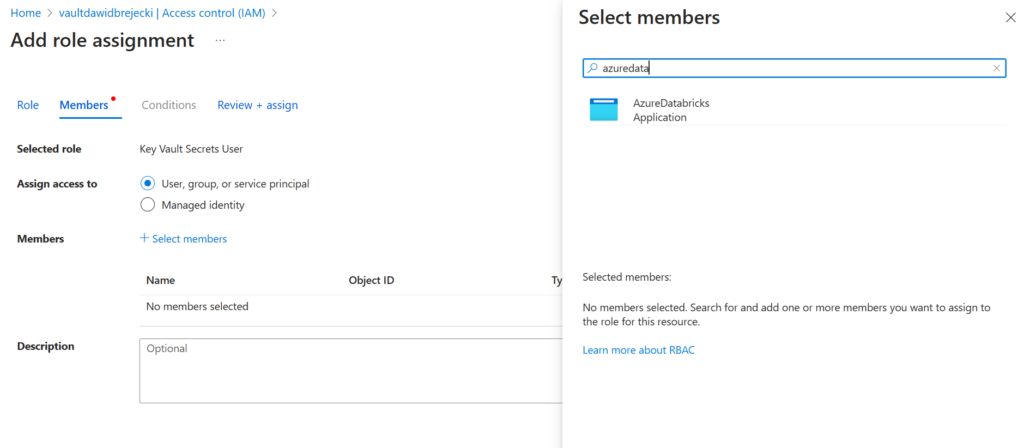
Ze strony Azure wszystko jest już skonfigurowane. Przenosimy się teraz do Databricks. Najpierw tworzymy scope (kontener przechowujący secrety), do którego dodajemy zasób Key Vault:
Dodajemy scope w Azure Key Vault. Nadajemy mu nazwę oraz wklejamy jego wartość generowaną podczas tworzenia secretu dla naszej aplikacji.
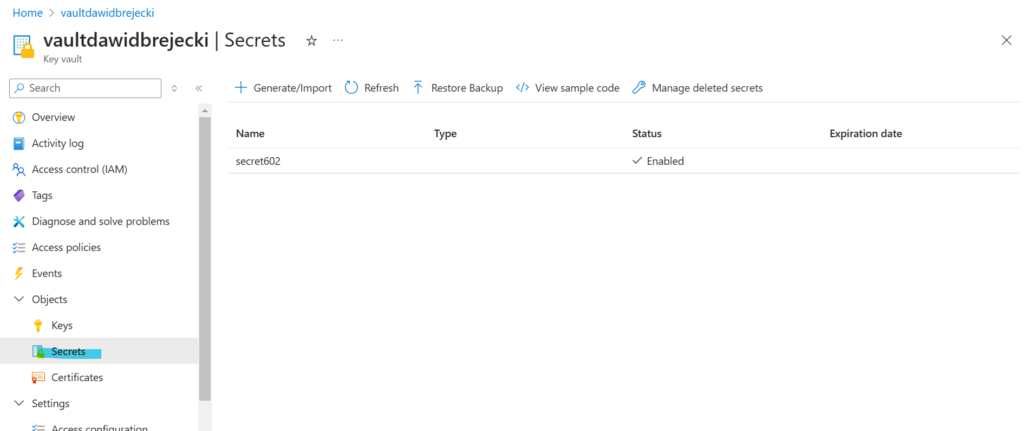
Nazwę secretu oraz informacje o Key Vault z properties przydadzą nam się w kolejnych krokach.
Ze strony Azure wszystko jest już skonfigurowane. Przenosimy się teraz do Databricks. Najpierw tworzymy scope (kontener przechowujący secrety), do którego dodajemy zasób Key Vault. Aby utworzyć secret należy zamienić nasz link otwartego notebooka:
https://adb-1747152247359772.12.azuredatabricks.net/editor/notebooks/397325365964120?o=1747152247359772#command/6084179303286158
Na następujący:
https://adb-1747152247359772.12.azuredatabricks.net/#secrets/createScope
Jak widać, dodajemy #secrets/createScope na końcu adresu azuredatabricks.net
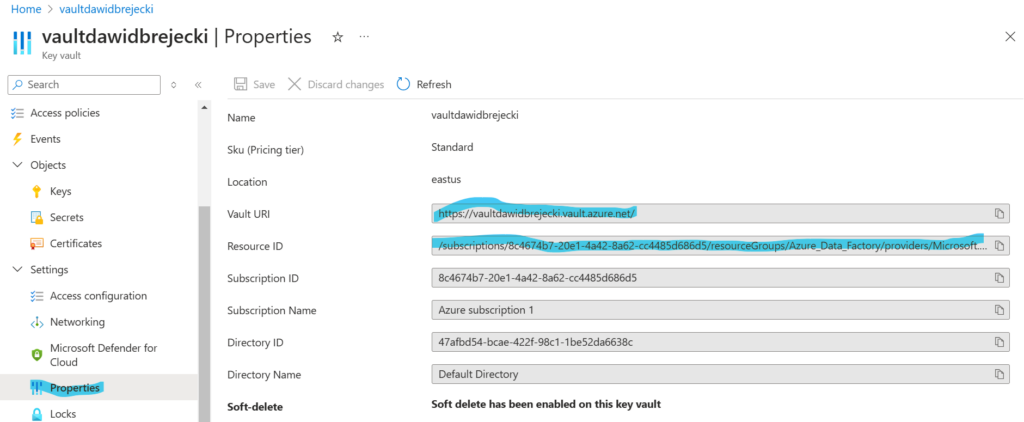
Przenosi to nas do strony, na której tworzymy scope dla naszego workspace. Podajemy Vault URL oraz Resource ID oraz nazwę scope (przyda się później)
Następujący kod umożliwia podłączenie się do Data Lake:
service_credential = dbutils.secrets.get(scope="scope602",key="secret602")
spark.conf.set("fs.azure.account.auth.type.datalakedawidbrejecki.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.datalakedawidbrejecki.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.datalakedawidbrejecki.dfs.core.windows.net", "3da8b5fb-c930-4dcb-8e5f-b99e9cd6f7a9")
spark.conf.set("fs.azure.account.oauth2.client.secret.datalakedawidbrejecki.dfs.core.windows.net", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint.datalakedawidbrejecki.dfs.core.windows.net", "https://login.microsoftonline.com/47afbd54-bcae-422f-98c1-1be52da6638c/oauth2/token")
Objaśnienia:
scope602 – oznacza nazwę Scope utworzoną w Databricks
secret602 – jest to nazwa secretu utworzona w Key Vault
datalakedawidbrejecki – nazwa Data Lake
3da8b5fb-c930-4dcb-8e5f-b99e9cd6f7a9 – client ID aplikacji
47afbd54-bcae-422f-98c1-1be52da6638c – tenant ID aplikacji
Pobieramy dane z pliku salesall.csv w kontenerze salesall z Data Lake:
df=spark.read.csv("abfss://salesall@datalakedawidbrejecki.dfs.core.windows.net/salesall.csv")
Zalecana strona z dokumentacją:
https://docs.databricks.com/en/connect/storage/azure-storage.html